7 Archaeobotany
This chapter presents the quantitative findings based on macrobotanical data from 190 case studies used in this research. The limitations of the dataset have been presented in both the materials (Chapter 3) and methods (Chapter 6) sections. Quantitative analysis of seed counts is unreliable due to the significant presence of outliers in many of the botanical assemblages. Therefore, presence/absence analysis is more appropriate. Plant remains can provide valuable insights into ancient agricultural practices and dietary patterns. While all calculations here are based on the presence of specific species in assemblages, a semi-quantitative approach to cereal abundance is also tested later in this chapter. However, this approach cannot be applied to other types of plant remains due to potential issues such as species rarity, under-representation, and outliers. The results will be presented in chronological order, providing ubiquity scores for each century under review. Additionally, for exploratory purposes, ubiquity has been calculated for southern, central, and northern Italy. The findings were initially interpreted qualitatively using the ubiquity scores. Later, Bayesian methods were used to model site richness and diversity scores, prompting a thorough study that included the development of multi-level models using Italian sub-regions as a predictor. The prevalence of free-threshing wheats and other rustic cereal crops in Italy’s three macroregions was studied using frequentist and Bayesian hierarchical models. Models for all plant macroremains species were developed using predictors such as context type, site altitude, average yearly temperature, and precipitation. This chapter also includes an evaluation of these models.
7.1 Ubiquity
In Chapter 6, we concluded that due to the numerous biases present in the sample, dealing with the archaeobotanical dataset warrants the use of a presence/absence analysis. One of the most prevalent types of presence/absence analyses for archaeobotanical remains is ubiquity. Technically speaking, ubiquity is a frequentist approach that only describes the presence of a particular species in a certain number of contexts. While there exist uncomplicated Bayesian substitutes, they still demand a certain degree of modelling or individual handling of each taxon purposes1. This level of detail is prohibitive for exploratory purposes. With this aim, ubiquity has been calculated (a) for each century, (b) for each Italian macroregion, stratified by chronological phase.
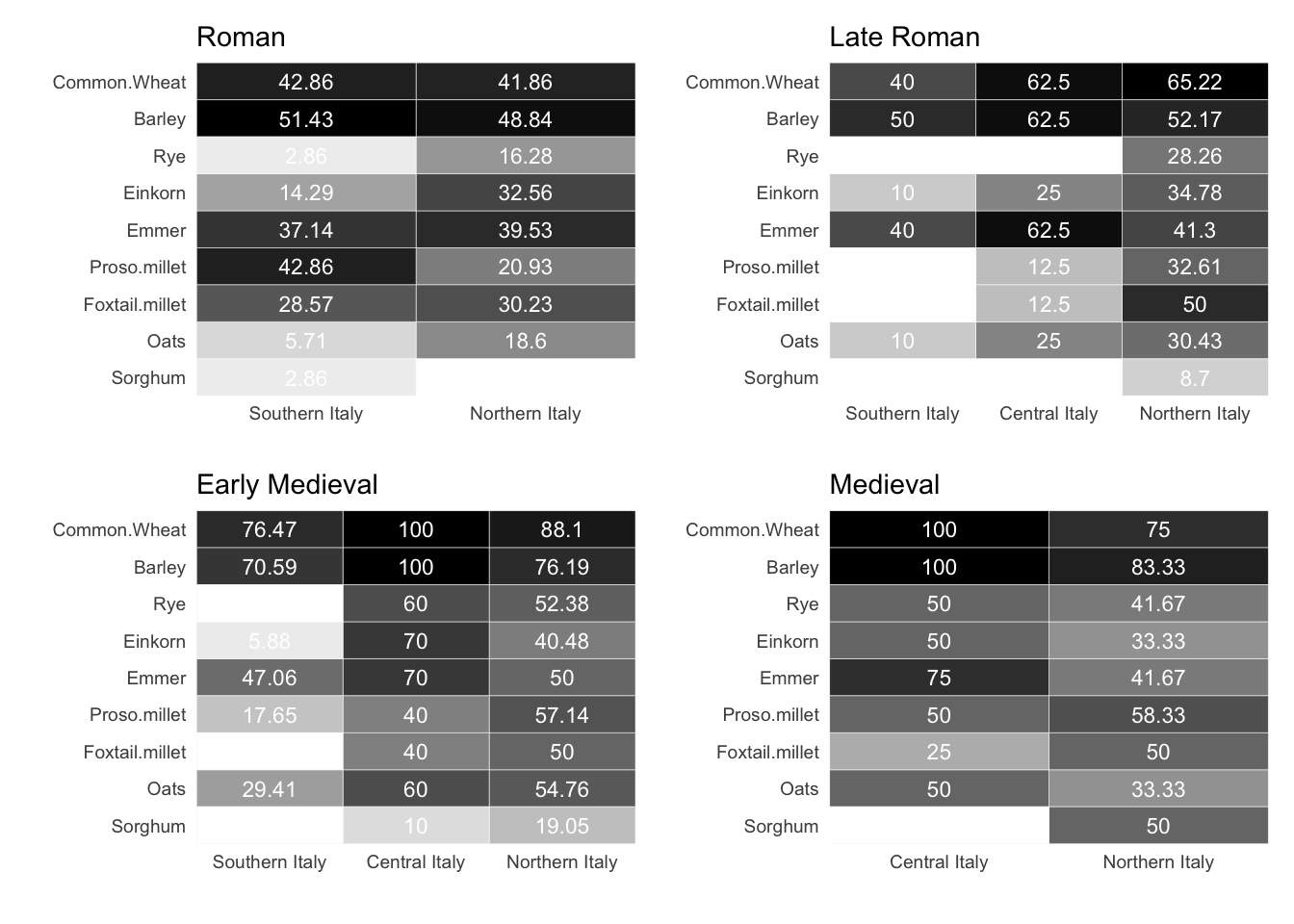
The heatmap in Figure 7.1 provides a good overview of the temporal trends of presence of cereals, legumes, fruits and nuts in the entire area under examination. Despite some trends are visible, it is important to remember that these results are just exploratory and they need to be compared with other predictors (i.e. context type, macroregion, etc.). The chart additionally presents the scientific names of all plants being researched, thereby allowing the usage of common English names later in this chapter.
7.1.1 Macroregional trends
In addition to investigating the ubiquity of each plant in every century, diachronic trends can also be derived by utilising the chronology and Italian sub-regions as predictive factors. This approach is only used as an initial form of data exploration, although this type of data stratification is risky with a data set that is not large enough. Sub-groups, such as Roman: central Italy, may not be informative due to their size. It is not feasible, for example, to carry out this research at the level of centuries. To subset the data from the northern, central and southern Italian regions, the R function Ubiquity_macroreg_chrono() (see ‘Custom functions’, Online Supplementary Materials) was created. To improve the readability of the plots, we categorised the taxa into cereals, legumes and fruits/nuts. We excluded some dataset columns, such as fruits that were only present in a few sites, from the plot.
7.1.1.1 Cereals
During the Roman age, cereals were commonly grown in both southern and northern Italy, with a few exceptions such as einkorn, rye, oats, and proso millet. Unfortunately, only three sites in Roman central Italy provided botanical assemblages, and their values have been omitted from the graph. The Roman Peasant Project (Bowes, 2020) has investigated these sites in Tuscany and has found three types of cereal: free-threshing wheats, emmer wheat and barley. Comparable ubiquity figures in both northern and southern Italy during the Roman age may imply similar production patterns throughout the Italian mainland, but more data is necessary. In the late Roman period, data on crop prevalence has been analysed for three macroregions, with southern Italy displaying the lowest reliability due to data being available for only five sites. The central Italian sites demonstrate that three crops are prevalent on 62.5% of the sites - free-threshing wheats, barley and emmer. Although other cereals are present, they are not as widespread. This triad of cereals is also widespread in southern Italy. Conversely, in the north of Italy, although free-threshing wheats and barley were important crops, they had to compete with other cereals such as millet, sorghum and rye. The latter crop witnessed a significant increase and was present in nearly 30% of the northern sites (as opposed to the Roman 16%). The early medieval period appears to have marked a shift in Italian agricultural practices, leading to greater regional variability in cereal production. In southern Italy, free-threshing wheats, barley, and emmer formed the main cereals during medieval times. These cereals are also prevalent in central and northern Italy, although these regions practise polyculture with a diverse range of cereals. The small number of samples from this period is due to the project’s chronological limit, which ends at the 11th century. Despite the brevity of the chronology, we can still make certain observations. Central Italy during the 11th century heavily relied on free-threshing wheats, barley, and emmer, whereas other more rustic cereals played a more minor role. Barley is the most prevalent cereal in northern Italy during this period, succeeded by free-threshing wheats, millets, and sorghum.
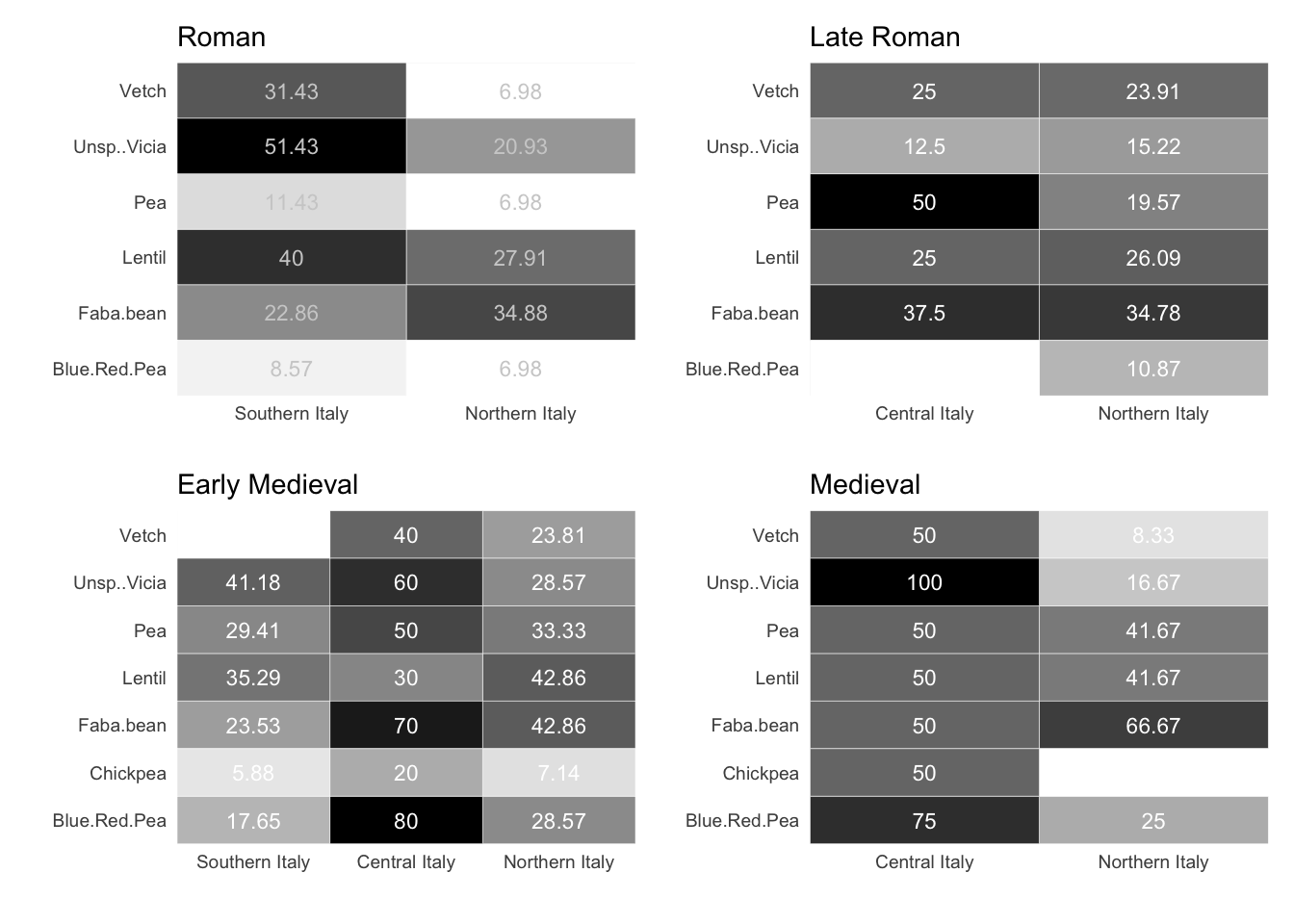
7.1.1.2 Legumes
In ancient Italy, legumes were grown for a number of reasons: they provided protein for human consumption, nitrogen for the soil and fodder for livestock. In southern Italy, during the Roman phase, vetch (Vicia sativa minor) and broad beans (Vicia faba) are present in 31% and 22% of the samples, respectively, while lentils (Lens culinaris) are present in 40% of the sites. During the late Roman age, broad beans were equally significant in central and northern Italy, with garden peas (Pisum sativum) present in 50% of the Central Italian sites. In the early medieval period, pulses were present in many central Italian sites, notably blue and red peas (or grass peas, Lathyrus cicera/sativus), broad beans, and others. Lentils and broad beans are also cultivated in nearly half of the northern Italian sites. The significance of pulses in central Italy is corroborated by the 11th century samples, as each species is prevalent in over 50% of the sites and Fabaceae can be detected in every sample. Broad beans were also found in 66% of the northern Italian sites.
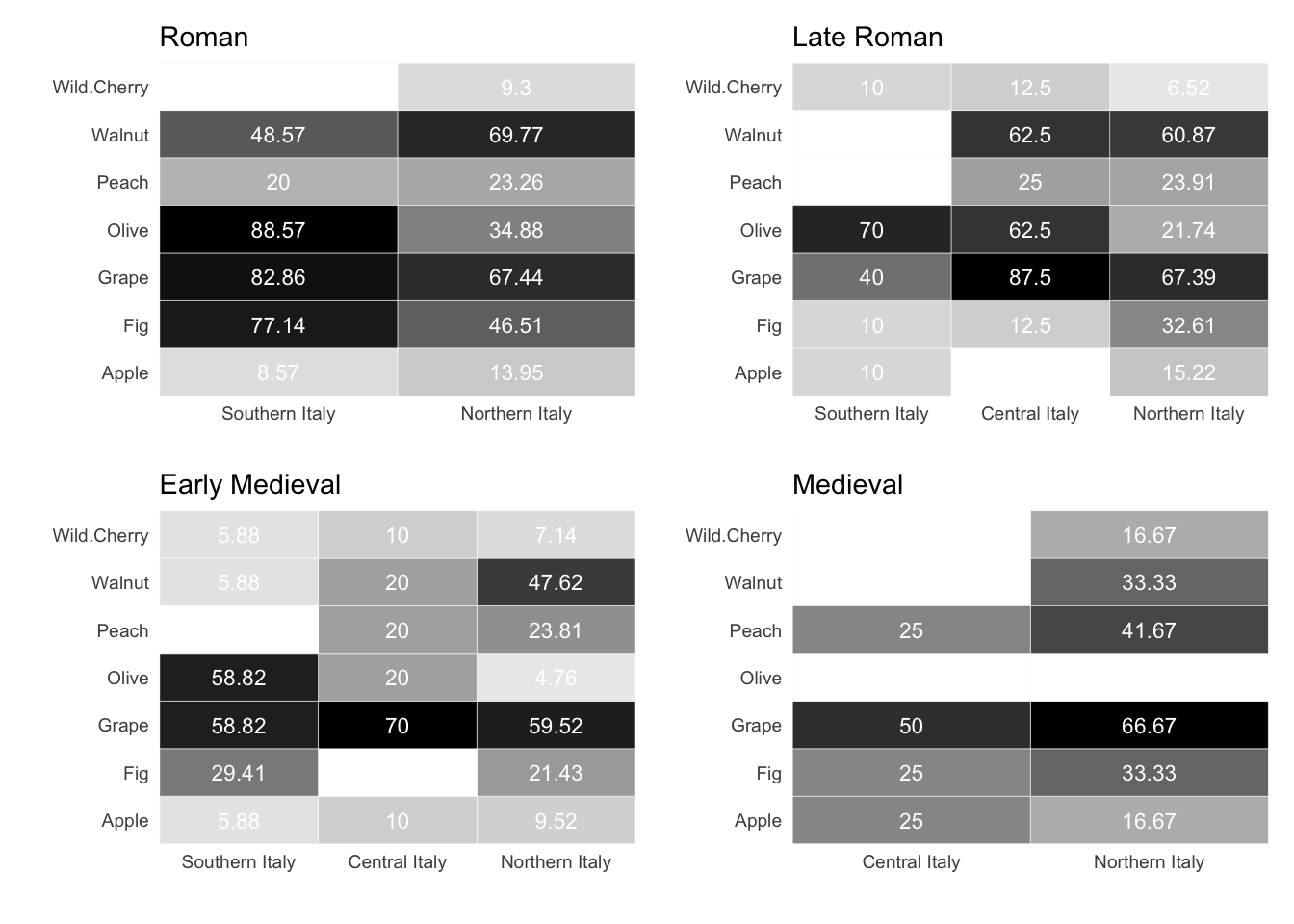
7.1.1.3 Fruits and nuts
Among the most commonly cultivated fruits in the Italian peninsula, olives and grapes were probably the most economically important species. Being sensitive to cold temperatures, olives are not surprisingly more prevalent in southern Italy, where they were found in over 88% of sites dated to the Roman phase and more than 58% of sites in later chronologies2. The cultivation of grapes played a significant role in the Italian agricultural landscape, exhibiting notably high ubiquity values in Roman southern Italy and in late Roman central Italy. Other fruit trees were also grown. The scores for their ubiquity varied, possibly because these species are present in smaller quantities in the excavations. This is especially true when the excavations are aimed at specific storage structures. Therefore, it may be more advantageous to investigate trends in fruits and nuts as collective categories, such as commonly domesticated fruits, rarer and wild fruits, and nuts. This is what we will do in the Bayesian models.
7.2 Site richness and diversity by chronology
Species richness is a measure used in ecology consisting simply in the counts of species found at a certain location. In archaeology, it can be informative for assessing how many different plants were found at a site. For the calculation, only sites that provided cereals, legumes, fruits and nuts have been used. Although this choice entails the loss of many observations, it was necessary in order to produce more credible and comparable results. The graphs below show extended credible intervals for groups with fewer observations.
The objective of the model was to determine the average plant diversity in each chronological sequence. A Poisson distribution was selected for the model as it is utilized when counts do not have a set upper limit (in contrast to a binomial distribution). The outcome variable is the richness (\(R_{i}\)) for each site \({i}\), calculated as follows
\[ R_{i} = \sum_{n=1}^{k} Species_{ni}\] where \(k\) represents the total number of species in a given site. The aim is to model the average richness \(\lambda_{i}\). The regression involves computing four intercepts, one for each chronology \(ChrID\), in addition to a varying slope for each observation (\(\beta_{[Observations]}\)). This will later help in quantifying the average deviation of the observations from the mean in each chronology (\(\alpha_{[ChrID]}\)). The Poisson regression formula is as follows, with weakly informative priors selected for the intercept and slope to ensure that the range of possible \(\lambda_{i}\) values stays within the outcome space:
\[R_{i} \sim Poisson({\lambda}_{i})\]
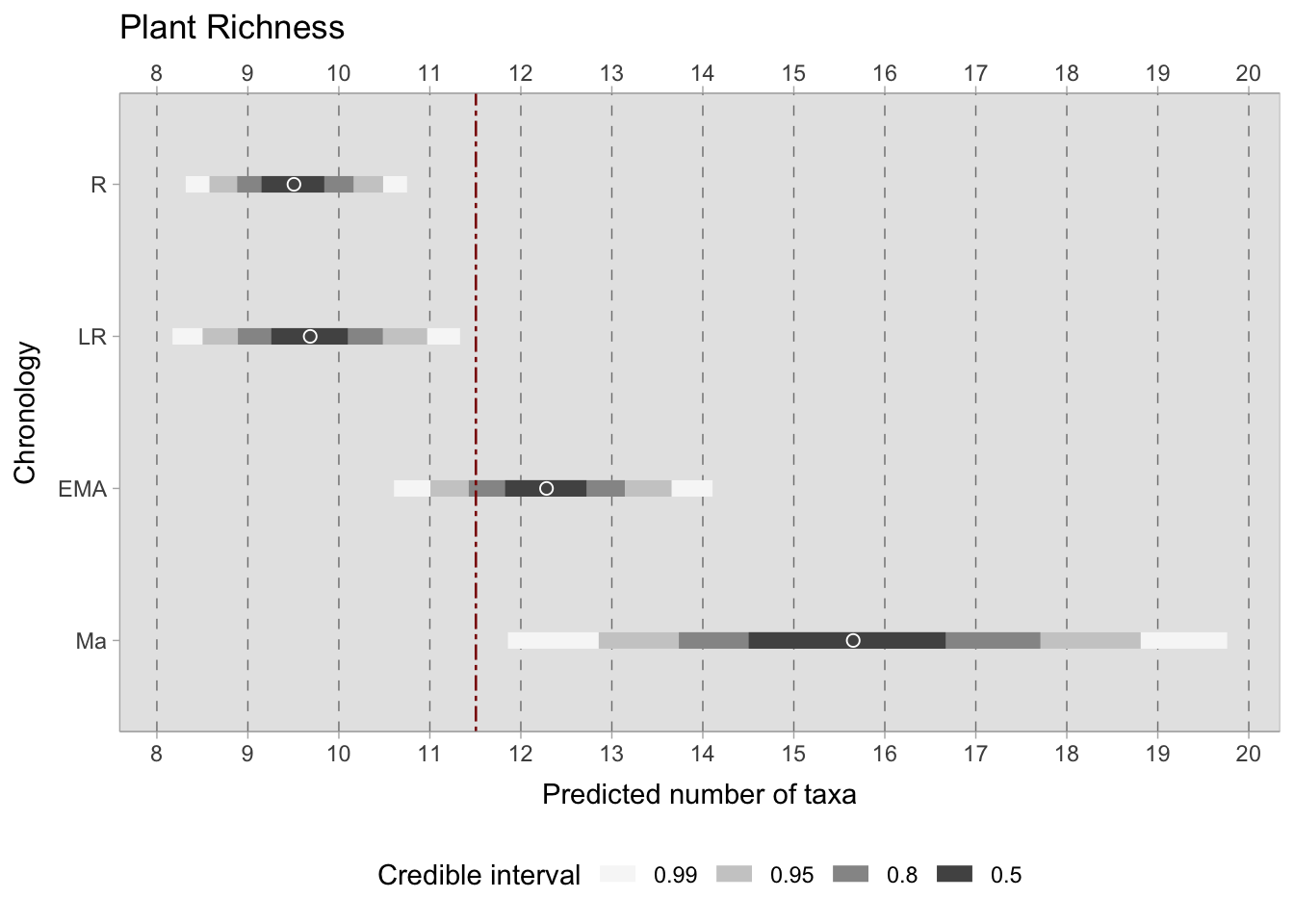
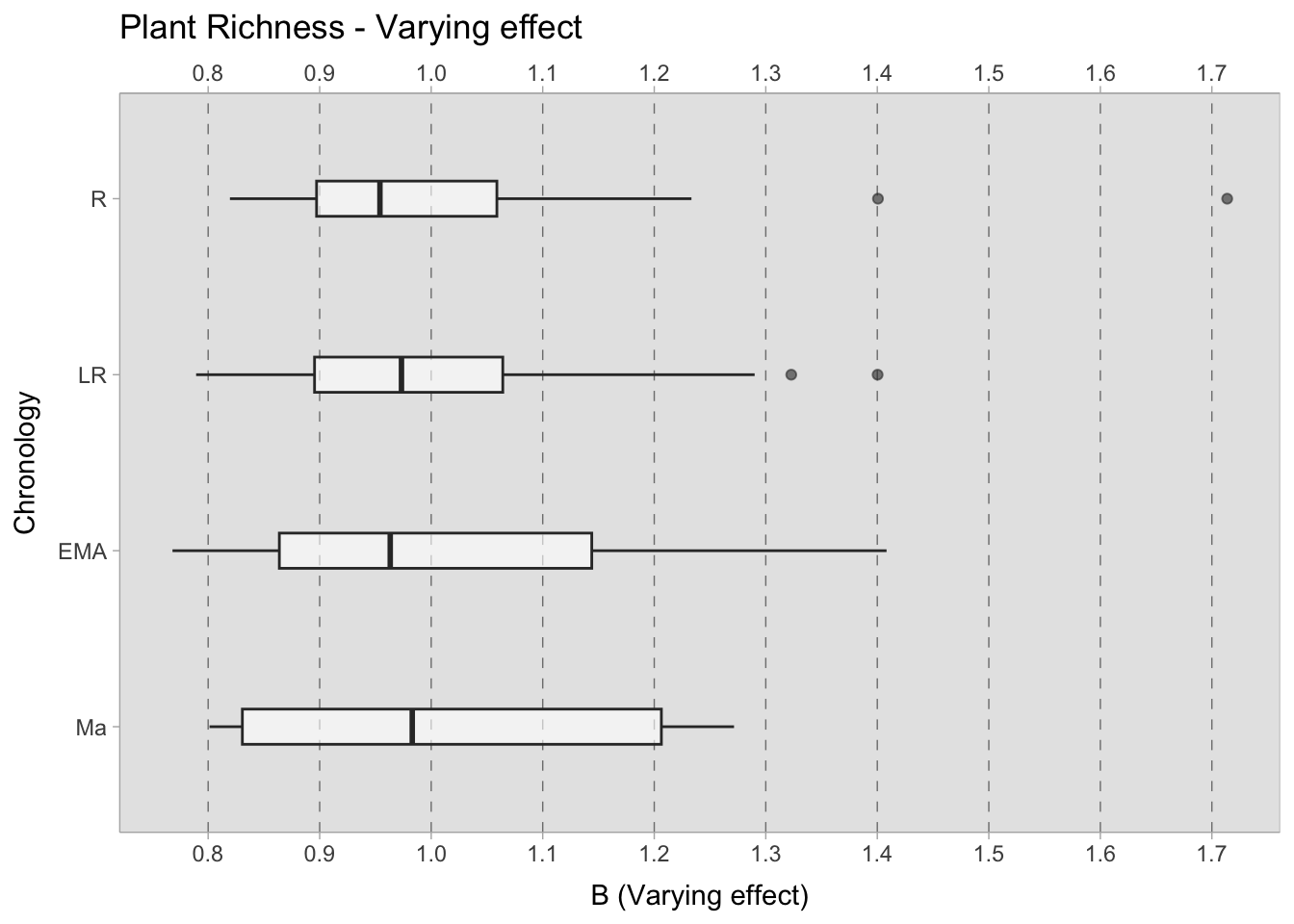
\[log {\lambda}_{i} = \alpha_{[ChrID]} + \beta_{[Observations]}\] \[\alpha_{[ChrID]} \sim Normal(3,0.5)\] \[\beta_{[Observations]} \sim Normal(0,0.2)\] The results illustrate that, within the 0.50 credible interval, the predicted species richness during the Roman and Late Roman period is approximately 9-10 species, which increase up to 12 species during the early medieval period, and between 14.5-16.5 post the 11th century; however, the credible interval is wider because of the scarce sample size. Despite their larger credible interval, even the most extreme values within the 0.99 credible interval have a minimum of 12 species, suggesting greater species richness during this period. When considering the varying effect, which illustrates the predicted deviations of each site from the mean (stratified by chronology), the samples from the 11th century onwards exhibit greater variability. Conversely, the samples from the Roman and Late Roman periods appear to form a more cohesive set of sites in relation to the number of species present. The median deviation of each site from the mean is consistently below one species in all chronologies.
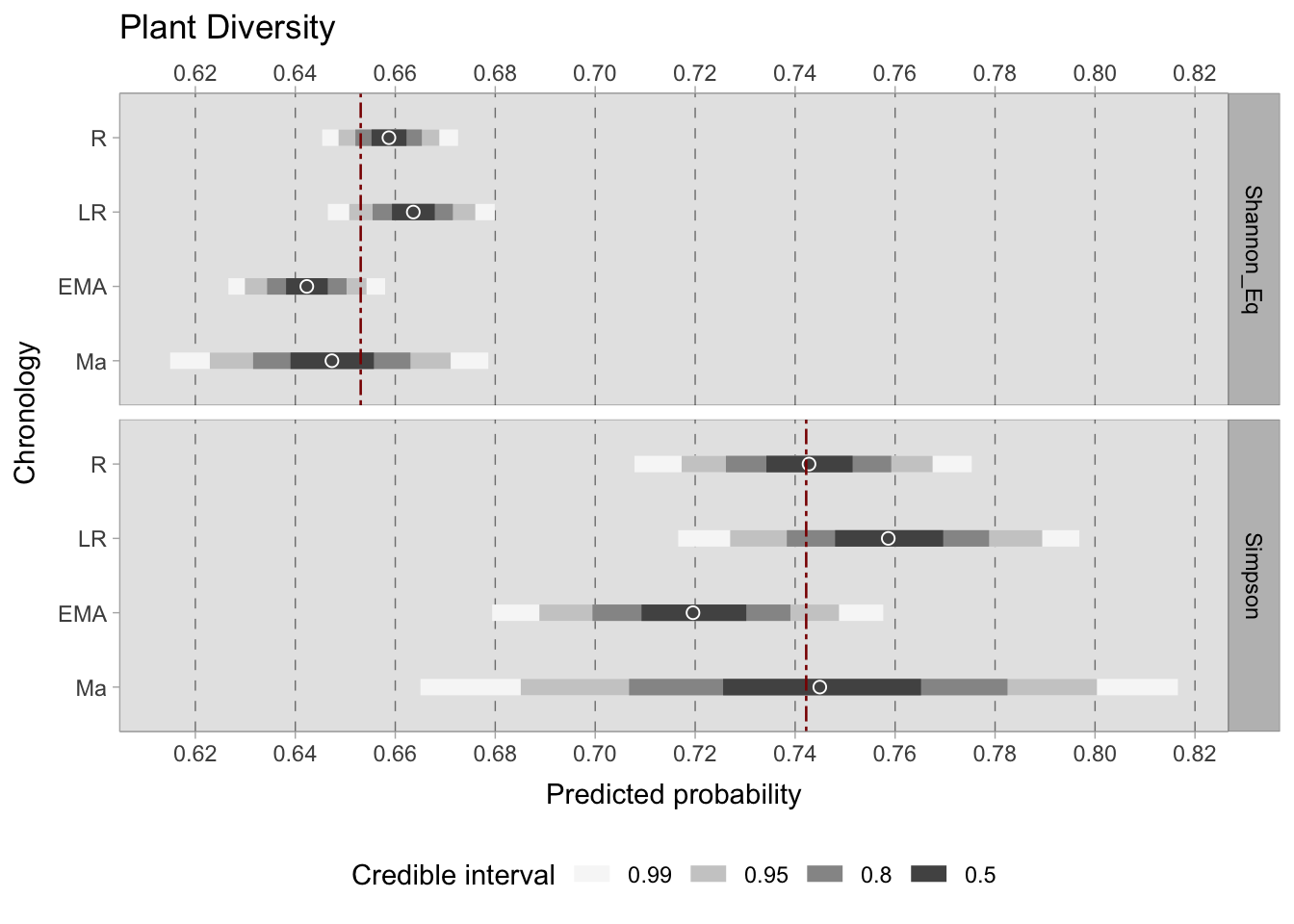
In contrast to taxon richness, taxon diversity considers the abundance of each taxon. It should be noted that in this dataset, this measurement can be skewed by samples where one taxon dominates to an extreme degree. For example, a sample collected from a processing or storage area is likely to exhibit one taxon that dominates the others. Although this was the reason for choosing to work with presence or absence data in this research, diversity indices are nonetheless provided for the sake of completeness. Specifically, we have computed two indices - Shannon equitability (\(E_{H}\)) and Simpson (\(D\)) - that range from 0 (complete inequality) to 1 (maximum diversity). These calculations can be performed using the vegan ecology R package functions. Only complete observations, consisting of cereals, pulses, and fruits/nuts, were considered for the calculation of richness indices. After computing both indices for each sample, these values were modelled using a beta distribution because it is bounded between 0 and 1. The resulting equation is as follows: \[ D_{i} \sim Beta(\mu_{i}, \phi_{i})\] \[logit(\mu_{i}) = a_{[ChrID]}\] \[a_{[ChrID]} \sim Normal(0,1.5)\] \[\phi_{i} \sim Exp(0.1)+2\]
Both indices have a range of values from 0 to 1, but they differ in their calculation methods (Nagendra, 2002). Therefore, direct comparisons between the values of \(E_{H}\) and \(D\) should not be made, even when displayed in the same figure. Rather, the relative trends within each index should be considered. Although the credible intervals differ (larger for the Simpson index due to increased variability between samples), the trends in diversity across chronological groups remain similar. During the Roman period, there was a lower diversity phase, followed by a slight increase in diversity in the Late Roman period and a subsequent decrease in the early medieval period. However, diversity then increased once more in the post-11th century samples. Nonetheless, the credible interval for this group is considerable and thus the results must be interpreted with caution.
7.3 Context type
After examining the principal chronological trends for plants’ distribution during the first millennium, we may add another factor to our inquiry, namely site type. We can expect dissimilar plants in a funerary context than in an urban site. Stratification of the dataset by site type is possible, but there is a challenge: the four chronologies we are studying also affect the availability, frequency and economic dynamics of site types. For example, the agricultural strategies employed by rural villas during the Roman and late Roman periods could differ based on political and economic events, which could affect the presence of certain taxa. We begin by drawing a directed acyclic graph (DAG), which illustrates how the Chronology node functions as the parent node of Site_Type, and it affects the Plant_Present value directly and indirectly through Site_Type. To account for this “backdoor path” (Pearl and Mackenzie, 2019), we block by Chronology and stratify the dataset by Site_Type. Since we have two categorical predictors of interest, an interaction index variable can be utilised to create separate intercepts for each chronology and context type. For instance, the Roman:Rural context type could be assigned an index of 1, while Roman:Urban could be assigned an index of 2, and so on. This interaction dummy index (\({[TCid]}\)) will determine the variation in intercepts (\(\alpha\)) across different context types. This is described in Section 6.6.1.
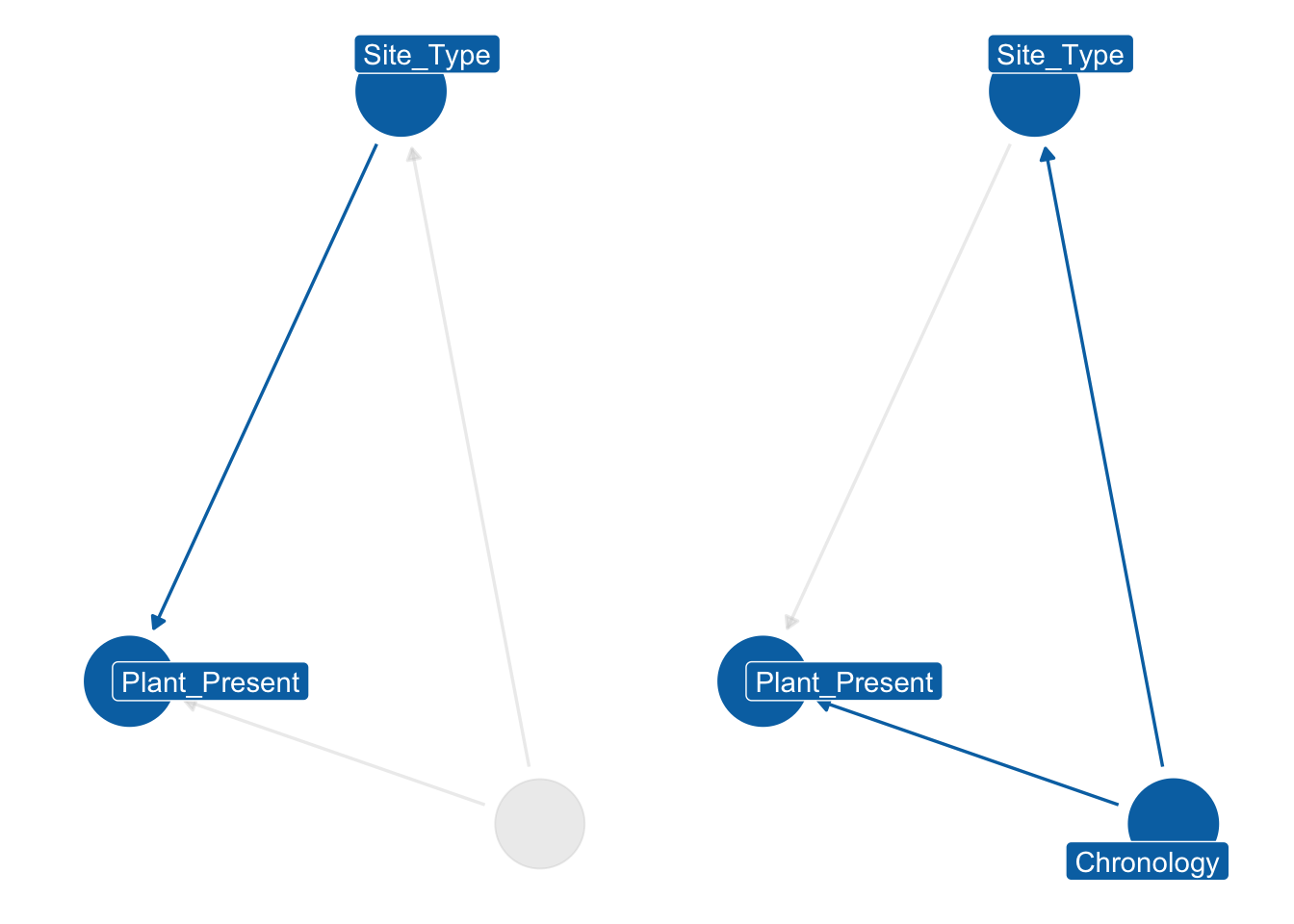
To assess the probability of the presence of a single or multiple taxa in each chronology and context, we opted to utilise a Binomial distribution. The \(F\) (an abbreviation for the term ‘found’) outlined on the left-hand side of the formula denotes the outcome variable - an indicator of presence/absence for the observation \(i\). If there is only one taxon, this value can either be 0 (absent) or 1 (present), with \(T\) (i.e. the number of trials) equalling 1. This effectively makes the Binomial distribution equivalent to a Bernoulli distribution. If the model includes more than one taxon, \(T\) represents the total number of taxa being modelled. For example, in the case of free-threshing wheats and barley, the model aims to evaluate the likelihood of these grains being present at a specific site type within a certain chronology. In this instance, the value of \(T\) for ‘noble’ grains is 2. The outcome variable \(F\) denotes the quantity of different ‘noble’ grains discovered on a specific site \(i\), with values ranging from 0 (no grains located) to 2 (the site contains both barley and free-threshing wheats). While it deviates from typical binomial distribution usage, this modification was essential because this study is handling presence/absence statistics. The model presented here is intercept-only, where the intercept \(\alpha\) holds an interaction index \({[TCid]}\). The model produces estimates for each context type and chronology under investigation.
\[ F_{i} \sim Binomial(T, \bar{p}_{i} ) \]
\[ logit(\bar{p}_{i}) = \alpha_{[TCid]} \]
\[ \alpha_{[TCid]} \sim Normal(0,1.5) \]
The rationale behind choosing a normally distributed prior for the intercept \(a\) is that it is weakly informative. Below, a simulation of the intercept prior.
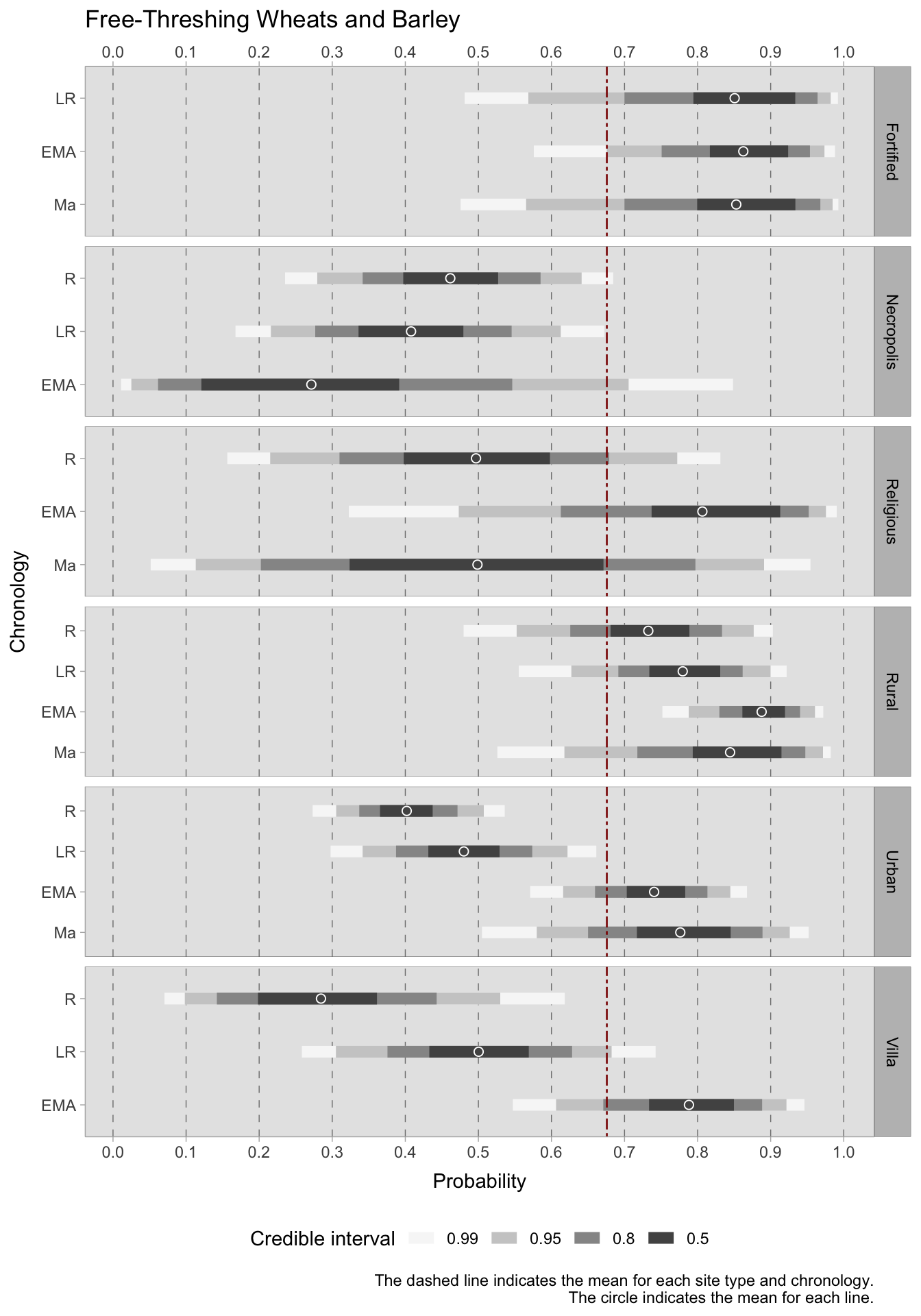
During the Roman period, free-threshing wheats and barley were primarily found on rural sites, where the predicted probability of occurrence (with a credible interval of 0.50) ranged between 0.68-0.78. The trend is positive, with an increase in predicted occurrence in later chronological phases. There is also an increasing tendency, although to a lesser extent, for urban sites and villas (at least until this type of settlement was abandoned). One site type consistently shows a strong presence of these grains from the late Roman to the medieval period: fortified sites (castra). Indeed, fortified settlements also exhibit a substantial presence of other types of cereal grains, including emmer, einkorn, and millets. If the average expected occurrence of more rustic grains throughout each chronology and type of site is approximately 0.31, in fortified sites, the average is about 0.65 during the late Roman and medieval eras and 0.59 during the early medieval period. In rural sites, too, rustic grains increase from the Roman to the early medieval period, reaching a peak of 0.43 in the medieval period and falling to 0.30 (but with a considerable credible interval) in the latest period after the 11th century. This pattern is also evident in urban and villa sites, which exhibit acceptably narrow credible intervals. However, credible intervals for religious sites, despite showing interesting results, are too wide due to their small group sizes.
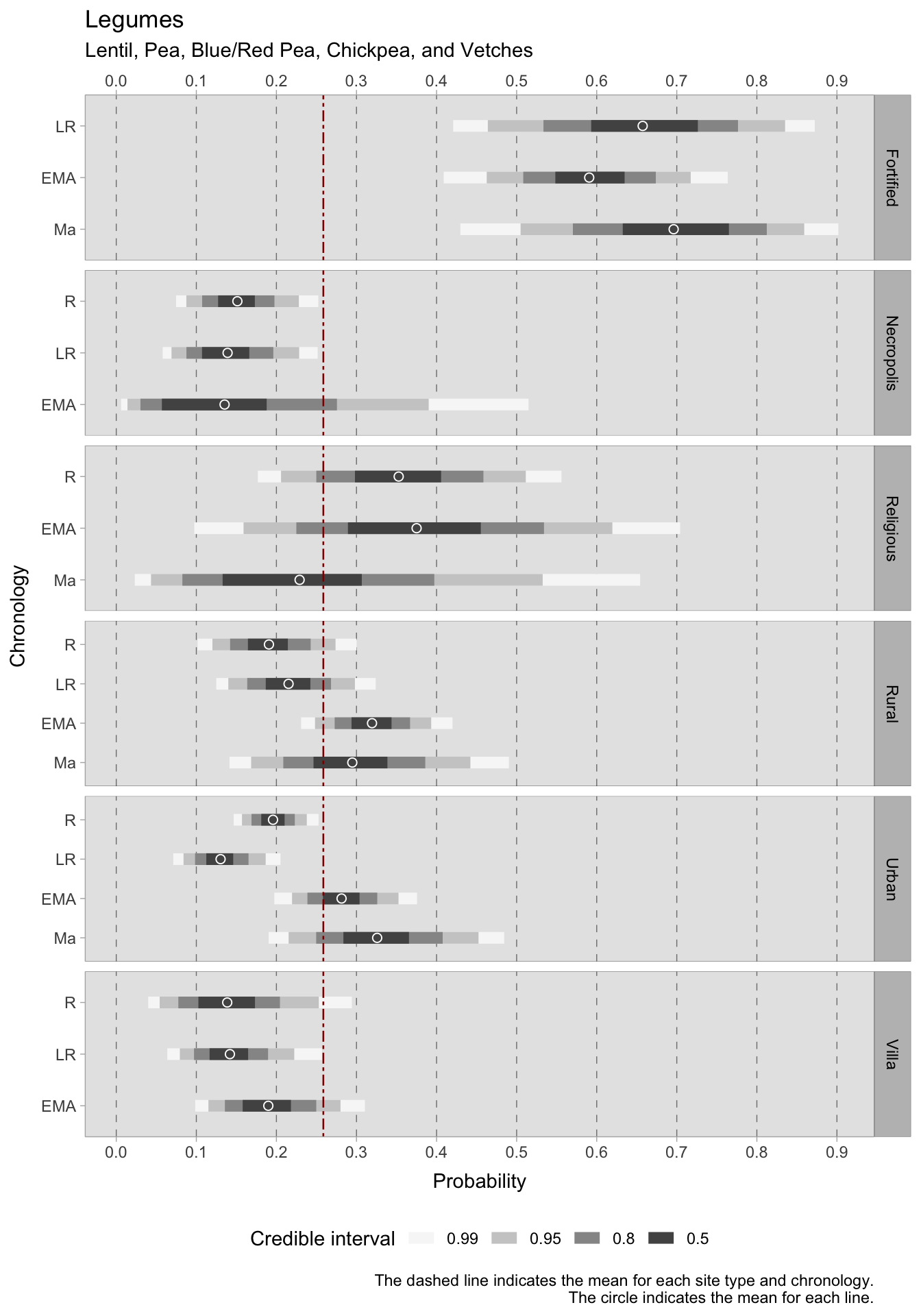
Regarding legumes, reliable conclusions can be drawn for most site types up until the 11th century. However, the length of credible intervals for religious sites makes any major informative conclusion uncertain for this site type. Legumes appear to always be a part of the rural landscape, found in both rural sites where pulses were particularly present during the early medieval (HDI = 0.30-0.34) and medieval (HDI = 0.25-0.34) periods, as well as in rural villas. In fact, during the early medieval period, probabilities increased in villas as well, with an HDI of 0.16-0.22. This trend is mirrored in urban sites as well. While probabilities during the Roman age hover below the mean of 0.25, the early Middle Ages witness a rise with an HDI of 0.25-0.30, reaching a peak in the later phase with an HDI of 0.28-0.37. This signals a notable uptick in the significance of pulses in the diet and farming. If the mean estimate of legume occurrence is consistently around 0.15 within necropoleis from the Roman to the early medieval period, then it is notable that legumes were important offerings at religious sites. During the Roman period, their significance ranged between 0.30-0.40, whereas in the early medieval period it was between 0.30-0.45. Regrettably, this group is relatively limited, and further observations are required from religious sites, as there were no late Roman samples, and the medieval samples show excessively wide credible intervals. While fortified sites display a wide credible interval in each phase, which may suggest considerable variability within the data, their 0.50 credible interval greatly surpasses the overall mean. During the late Roman period, the HDI fluctuates between 0.59-0.73. In the early medieval period, the HDI is marginally lower, ranging between 0.55-0.64, before increasing again in the 11th century samples, where it ranges between 0.64-0.76.
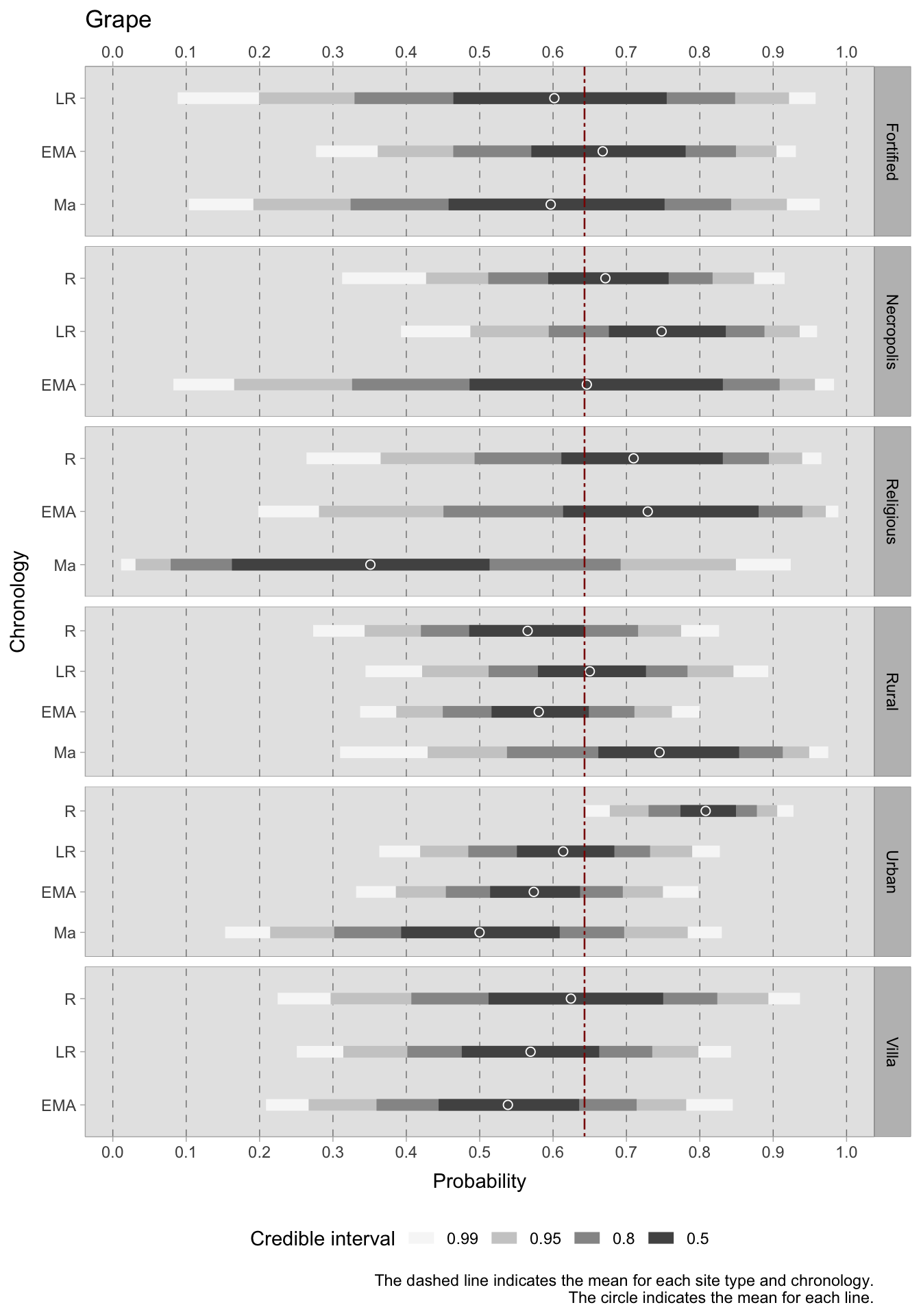
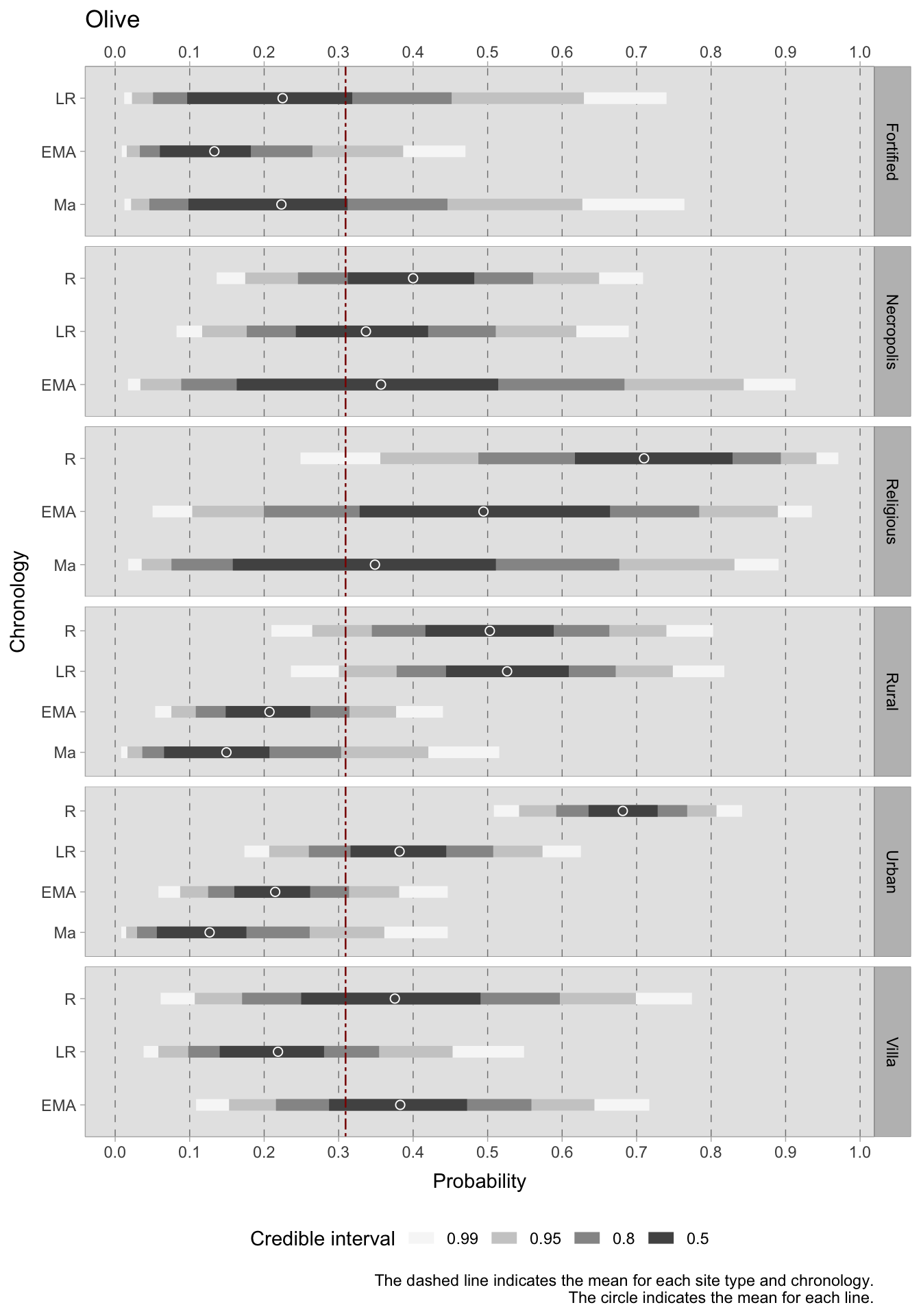
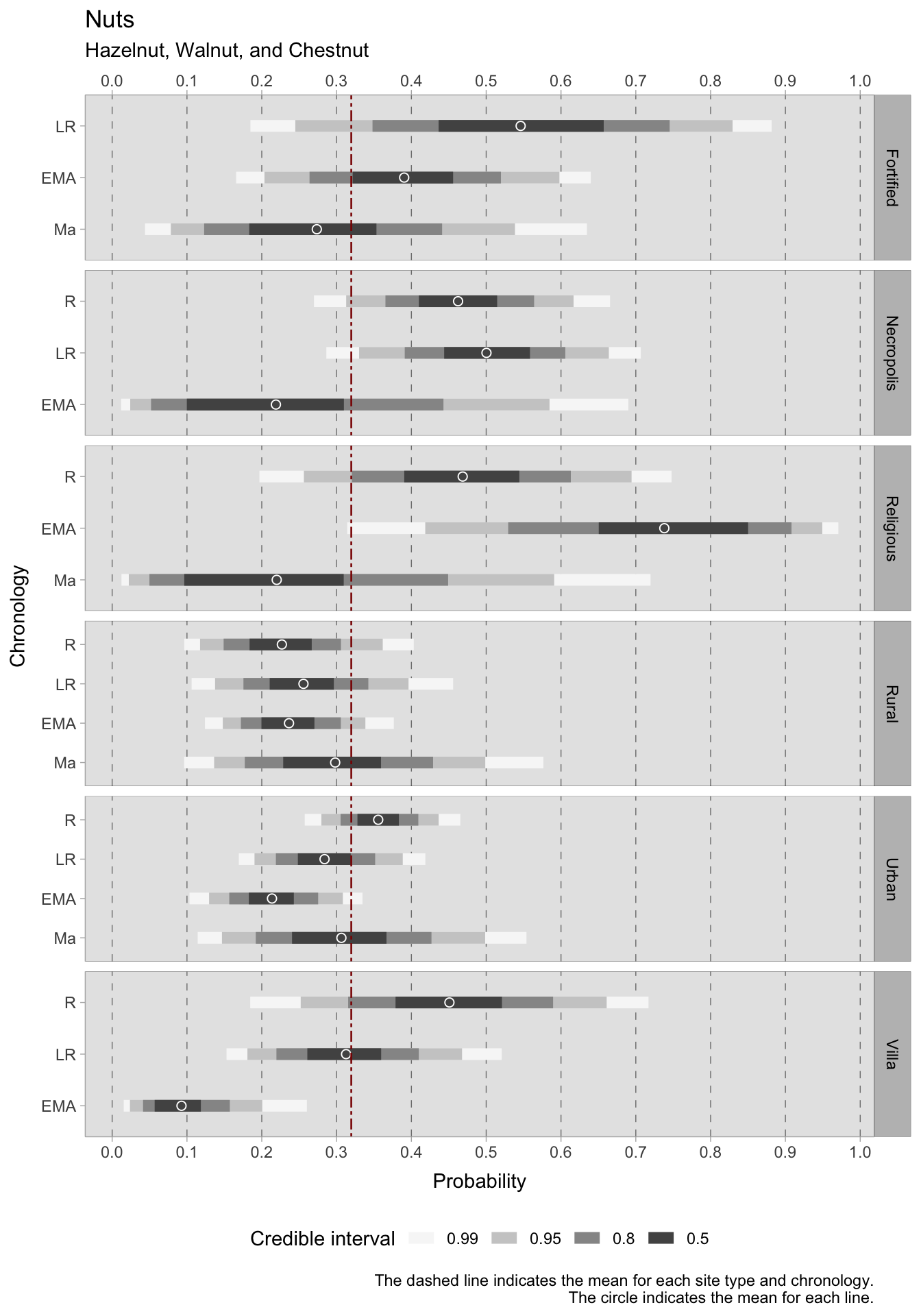
For what concerns the two primary cash crops, grapes and olives, it is challenging to draw conclusions with regards to site type and chronology as predictors. This is due to the small group sizes and variability between sites, which result in particularly broad credible intervals. In general, there are indications of a decrease in grape cultivation in both urban and rural areas. In the rural setting, however, the trend is fluctuating, with a positive turn in the late Roman era and a new decline in the early Middle Ages. With such wide credible intervals covering a significant portion of the probability space, it is probable that the data was unable to overcome the prior, leading to high uncertainty. Further data or a more informative prior (although this may introduce subjectivity) may be necessary. The olive plots have narrowed the credible intervals range slightly. During the Roman period, olives were frequently present in urban sites with a range of 0.63-0.72 (credible interval = 0.50) and religious sites with a highest density interval ranging between 0.61 and 0.81. In rural sites, olives were also prevalent, with an estimated mean of around 0.50 in the Roman period and 0.52 in the late Roman period. However, in later periods, there was a sharp decline in olive production. This decline commences in the late Roman period for both urban and rural villa sites, though the latter does experience a renewed positive HDI in the early medieval period. Generally, the average occurrence of grapes (although with all the limitations imposed by such large credible intervals) is higher than that of olives. This may be attributed to numerous samples in the database coming from northern Italy, which is less suitable for olive cultivation. The credible interval ranges for the models of nuts, i.e. hazelnuts, walnuts and chestnuts, are narrower and more informative compared to those of the grape/olives models. This implies that there is less variability in the dataset available for this category. During the Roman period, the highest HDIs for nuts are found in religious sites, necropoleis, and rural villas. However, the credible intervals for these categories are large. The estimated mean HDI for urban sites during this period is approximately 0.35, while for rural sites, it is around 0.22. During all the subsequent periods, the mean predicted occurrence remains below the overall mean of 0.31 for both types of locations, with a potential downward trend for urban sites.
The group that exhibits the most significant decline is rural villas, which decreased from an average Roman estimate of 0.45 to an average of 0.09 in the early medieval era. Villas show a similar decrease in the frequency of domestic fruits (apple, fig, melon, peach, pear, plum, date), but with credible intervals of considerable size.
During the Roman era, fruits were abundant in urban locations, becoming less prevalent in subsequent periods, only to rise again in samples after the 11th century. Funerary sites also exhibit high HDI averages for domestic fruits (0.23 in the Roman period and 0.28 in the late Roman period). In contrast, there is a gradual rise in the occurrence of cultivated fruits in rural areas between the Roman and medieval eras. In addition to larger fruits, our model encompasses the consumption of different types of berries and other less common fruits such as sour cherry, cornelian cherry, wild cherries, elderberry, blackthorn, blackberry, and strawberry. It appears that the presence of these fruits was ubiquitous, albeit in minor quantities. Upon closer inspection of contexts with more reliable credible intervals, a positive trend is observable in rural sites from the Roman to the medieval era. While urban sites exhibit fluctuations, they appear to have a higher consumption of berries, with HDI values exceeding the overall mean. The trend in rural villas is less pronounced: during the Roman period there is a substantial variability that resulted in a larger credible interval, whereas the late Roman period’s average is around the overall mean of 0.10. Afterwards, the average drops to 0.04. For the Roman and late Roman period, estimated averages of 0.04 and 0.07 are identified in necropoleis, respectively.
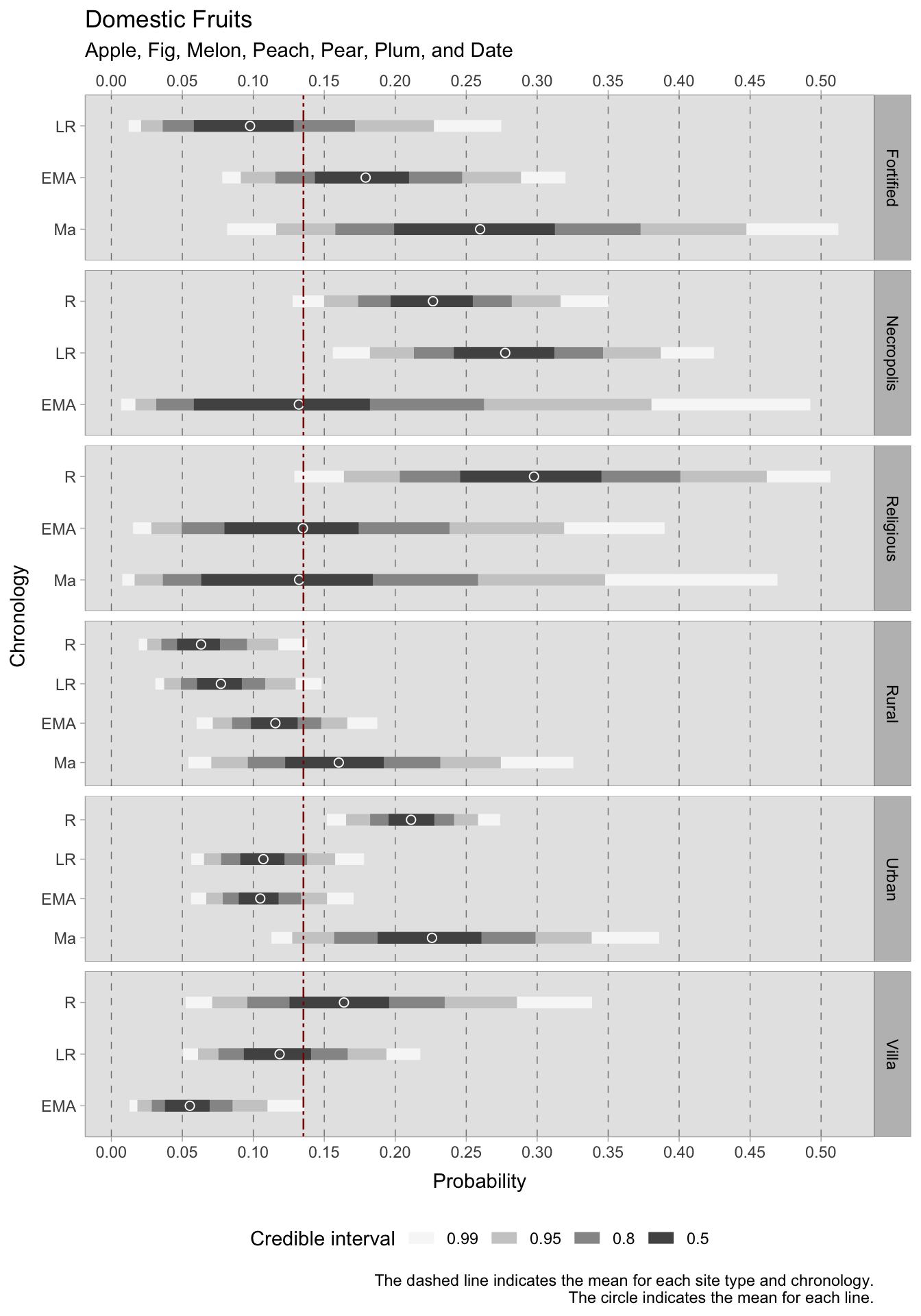
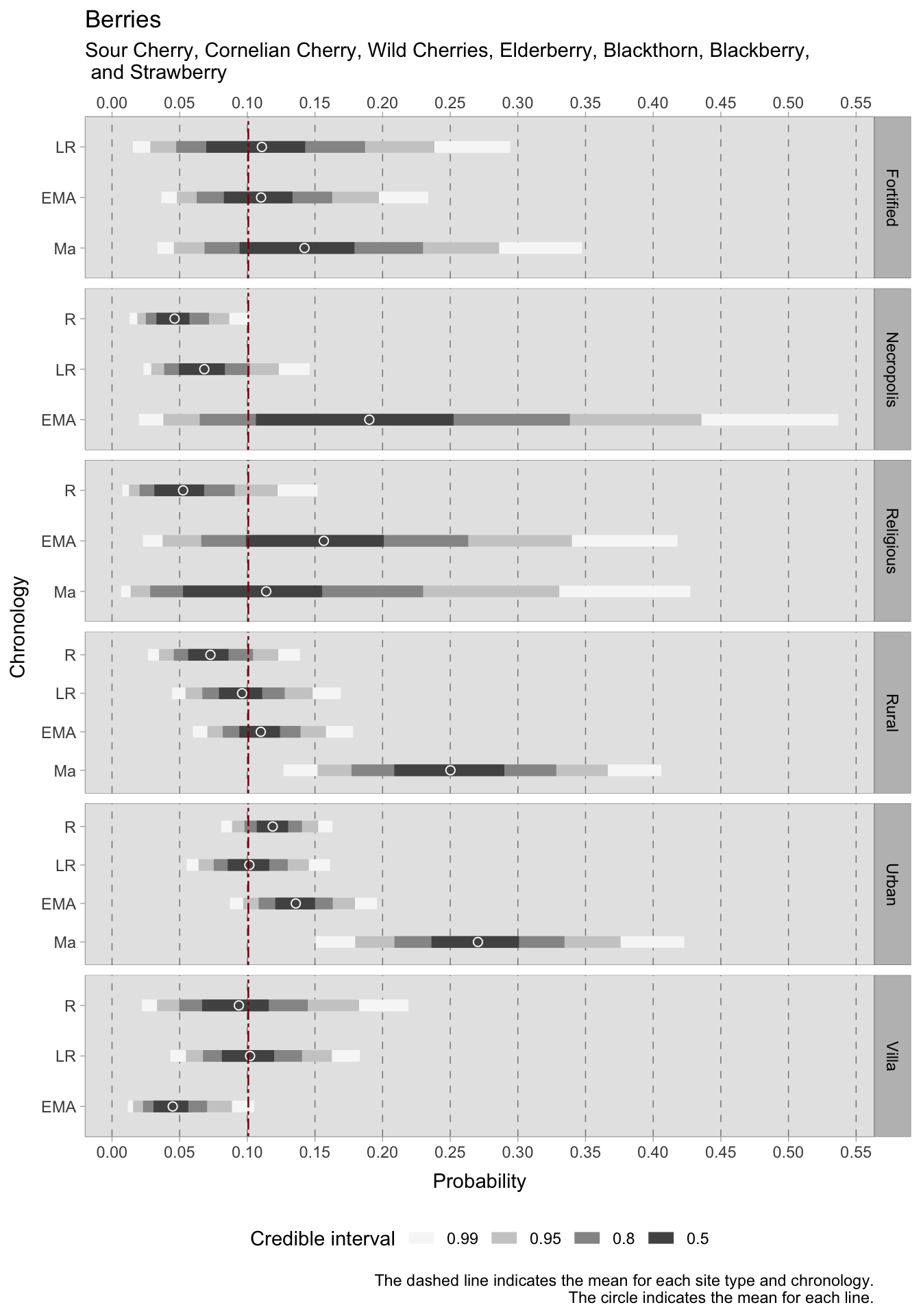
7.3.1 Species richness in urban contexts
In addition to examining the predicted occurrence of particular plant species within the selected contextual classifications, we found it instructive to examine plant richness. Yet, as previously stated in this chapter, subsetting data based on site type results in very narrow groups that provide unreliable information. Of all the context categories, urban sites displayed the greatest frequency of sites for every chronology analysed. For this reason, and because of our specific interest in the early medieval urban garden phenomenon, we calculated the richness of plants in urban settings for each stage. To ensure accuracy, we excluded contexts that did not report all three types of plant taxa under examination - namely cereals, fruits/nuts, and legumes. This correction carries significant drawbacks because it eliminates sites where the exclusion of certain plant categories may have been intentional (such as storages). However, despite considerable fluctuations in the numbers (particularly for the 11th century CE, which comprises only two samples after the correction), the overall trend remains similar to the previous one. Plant richness slightly decreases in urban contexts after the Roman period; however, early medieval cities exhibit a higher plant richness than the Roman and late Roman phases. In the 11th century, plant richness increases even further.
| Chronology | Richness | Samples | Richness* | Samples* |
|---|---|---|---|---|
| R | 6.5 | 44 | 8.45 | 22 |
| LR | 5.9 | 24 | 7.2 | 10 |
| EMA | 7.2 | 25 | 9.6 | 8 |
| Ma | 9 | 8 | 17.5 | 2 |
7.4 Macroregion
7.4.1 Cereals
The central focus of this chapter revolves around cereals, given their pivotal economic importance during the first millennium CE. The exploration begins with two Bayesian models that vividly depict the estimated occurrence of free-threshing wheats, barley, and other more rustic grains across each chronological phase under consideration. Moving forward, our attention shifts to the richness of cereals within each sub-region. We delve into an examination of the distances between the northern and southern Italian cereal datasets during the early Middle Ages, presented as a compelling case study. Unlike the Bayesian models, this case study employs a frequentist approach, allowing for a comparative analysis of results obtained through distinct methodologies and perspectives. As we unravel the findings, it becomes evident that both the Bayesian models and the frequentist approach converge on the same conclusions. Despite their differing methodologies and analytical angles, the unified outcomes contribute to a comprehensive understanding of the dynamics surrounding cereal cultivation in northern and southern Italy during the early Middle Ages.
7.4.1.1 Free-threshing wheats and barley
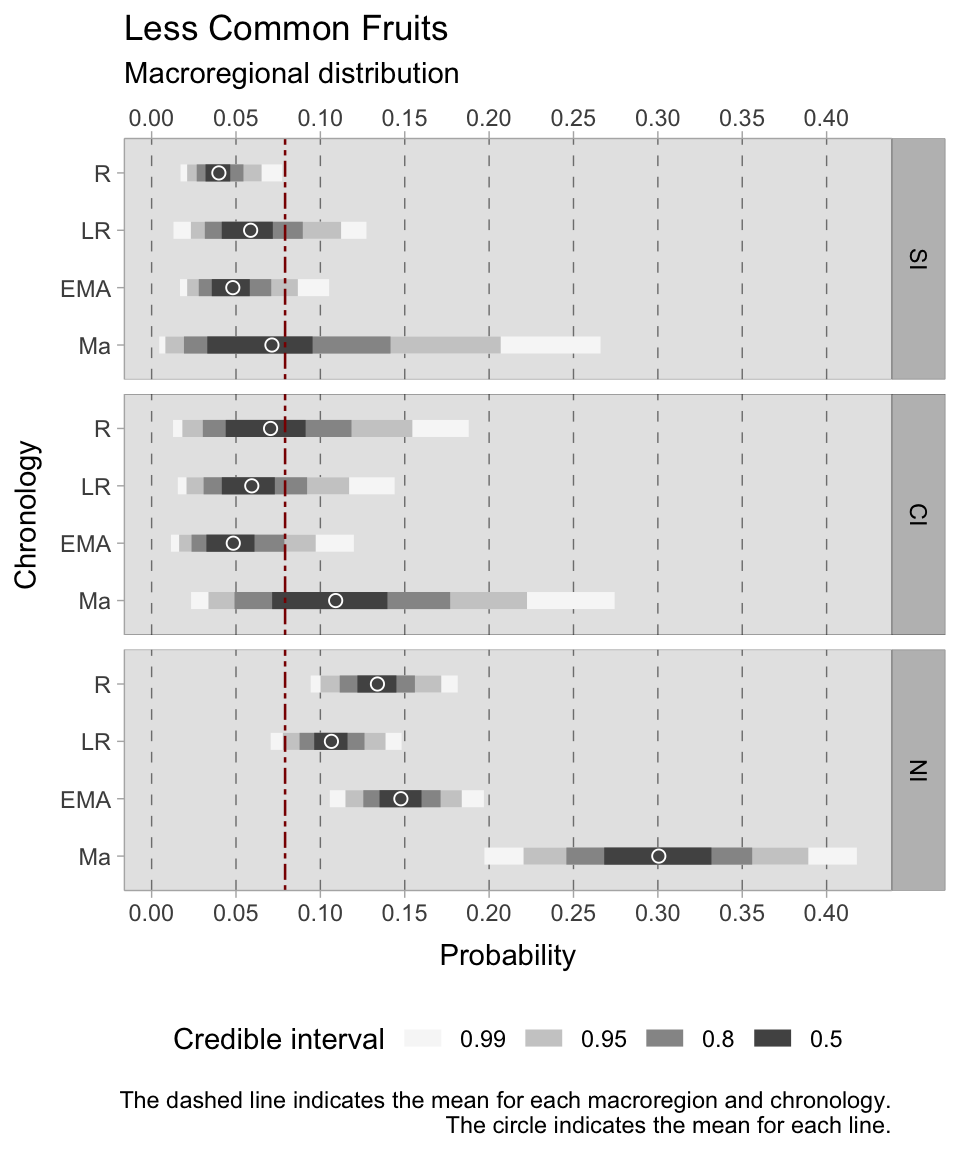
In addition to considering chronological and context type models, another important variable that has been examined in this study is Macroregion. This allows us to divide the Italian peninsula into three regions (southern, central, and northern) and investigate more specific geographic questions. Due to the limited amount of data available, it is not however feasible to build on the previous model and incorporate this variable into the analysis. Additionally, including three categorical predictors would make it difficult to interpret the results. To account for the influence of Macroregion, we can stratify the dataset by southern, central, and northern Italy, similar to how we stratified by Site_Type. It is important to also consider chronological stratification as different dynamics were occurring in the areas under observation. Therefore, we can block by Chronology and stratify by Macroregion to investigate the influence of geographic location on animal husbandry and consumption patterns.
The chosen distribution is a Binomial where \(F\) (short for ‘found’) on the left side of the formula is the outcome variable—a presence/absence indicator for the observation \(i\). In the case of a single taxon, the value can either be 0 (for absence) or 1 (for presence) and the \(T\) is 1 (i.e. Bernoulli distribution). If the model is for more than a single taxon, the \(T\) is the total number of taxa that are being modelled. The model presented below is an intercept-only model, where the intercept \(\alpha\) carries an interaction index \({[REGid]}\) as the model will provide estimates for each macroregion and chronology under examination. For instance, Roman: southern Italy is labelled as 1, Roman: central Italy as 2, and so forth.
\[ F_{i} \sim Binomial(T, \bar{p}_{i} ) \]
\[ logit(\bar{p}_{i}) = \alpha_{[REGid]} \]
\[ \alpha_{[REGid]} \sim Normal(0,1.5) \]
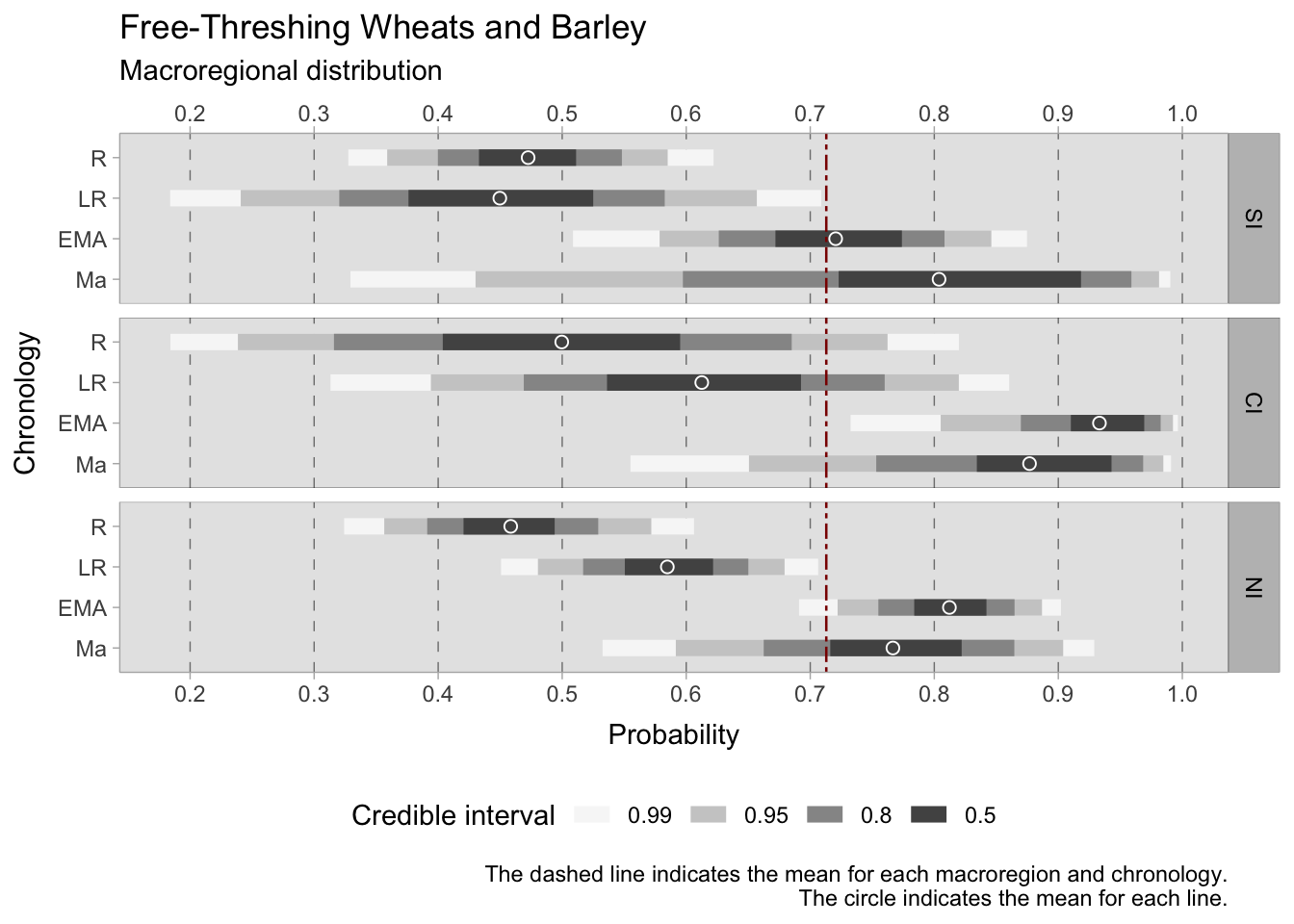
While cereals are particularly important in our analysis, the interpretation of the results of this model is problematic and immediately reveals the group imbalances. The credible intervals for northern Italy are narrow and informative, considering the usage of a weakly informative prior. On the other hand, the range of estimates for southern and central Italy requires careful consideration. Nonetheless, it is still possible to draw conclusions by analysing the regions of the graphs where the majority of the probability estimates are located. During the Roman period, the mean estimated probabilities of discovering free-threshing wheats and barley was similar in all three sub-regions (SI = 0.48, CI = 0.50, NI = 0.46), although the credible interval for central Italy is quite large requiring additional archaeobotanical data to increase specificity. In the late Roman period, the credible intervals are quite large both for southern Italy (where the 0.50 probability region ranges between 0.38 and 0.52) and central Italy (where the 0.50 probability region ranges between 0.53 and 0.69). Conversely, the 0.50 credible interval for northern Italy is between 0.55 and 0.62. During the early medieval period, there was a marked increase in estimates across all three regions. Central Italy had the highest peak, ranging from 0.91 to 0.97, while northern Italy reached 0.78 to 0.84, and southern Italy attained 0.67 to 0.77. The smaller post-11th century dataset yields broad credible intervals, suggesting a possible positive growth in southern Italy, while mean estimates for central and northern Italy reflect a minor decrease.
7.4.1.2 ‘Minor’ grains
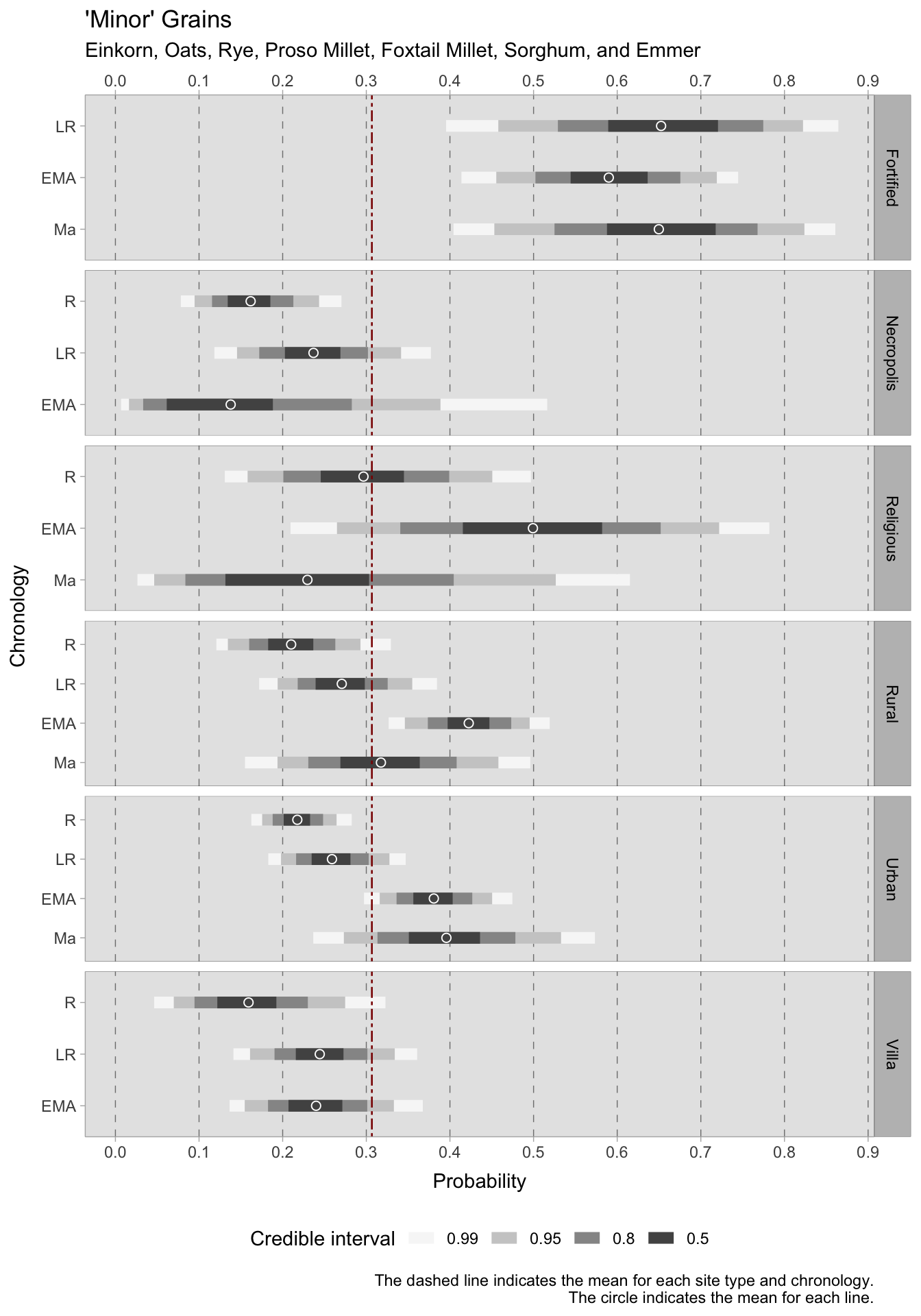
The model for ‘minor’ grains (emmer, einkorn, foxtail millet, broomcorn millet, rye, sorghum) in the Italian macroregion uses a Binomial distribution where \(F\) (short for ‘found’) on the left side of the formula is the outcome variable—a presence/absence indicator for the observation \(i\). As there are seven types of ‘minor’ grains under investigation, the binomial will take 7 as maximum (\(T\)). This model effectively shows the probability of a single site to be reliant on more rustic grains. Emmer for instance, is ubiquitous in Italy, but in many cases it is the only hulled grain found among other cereals in a context. The presence of other cereals on a site can in fact be useful in understanding the local rural economy. The model presented below is an intercept-only model, where the intercept \(\alpha\) carries an interaction index \({[REGid]}\) as the model will provide estimates for each macroregion and chronology under examination.
\[ F_{i} \sim Binomial(7, \bar{p}_{i} ) \]
\[ logit(\bar{p}_{i}) = \alpha_{[REGid]} \]
\[ \alpha_{[REGid]} \sim Normal(0,1.5) \] After examining the posterior distribution, the credible intervals reveal a striking coherence in the dataset, marked by a lack of excessive dispersion. However, central Italy deviates as the group sizes are small, which leads to larger credible intervals. Divergent patterns among Italian sub-regions can already be observed in the Roman age. In southern Italy, the 0.50 HDI is confined within the tight range of 0.18 to 0.21. Contrastingly, central Italy showcases a broader span from 0.07 to 0.13, while the North falls within the range of 0.22 to 0.24. In particular, the North has a considerably short credible interval, suggesting consistency and a substantial volume of observations. We observe diverging trends as we transition into the late Roman period. Southern Italy maintains a narrow range of 0.08-0.12, whereas central Italy experiences a higher degree of variance from 0.17 to 0.23. The north shifts towards ‘minor’ grains, reflected in an expanded interval of 0.31-0.35. During the early Middle Ages, both central and northern Italy surpass the overall mean of 0.23, with HDIs ranging between 0.46-0.54 and 0.44-0.48, respectively. A growing disparity between these regions and southern Italy becomes evident, where the HDI hovers between 0.13-0.17. Despite the broad credible intervals for post-11th-century samples, the estimated means consistently uphold the preceding trends, albeit with a subtle downward tendency.
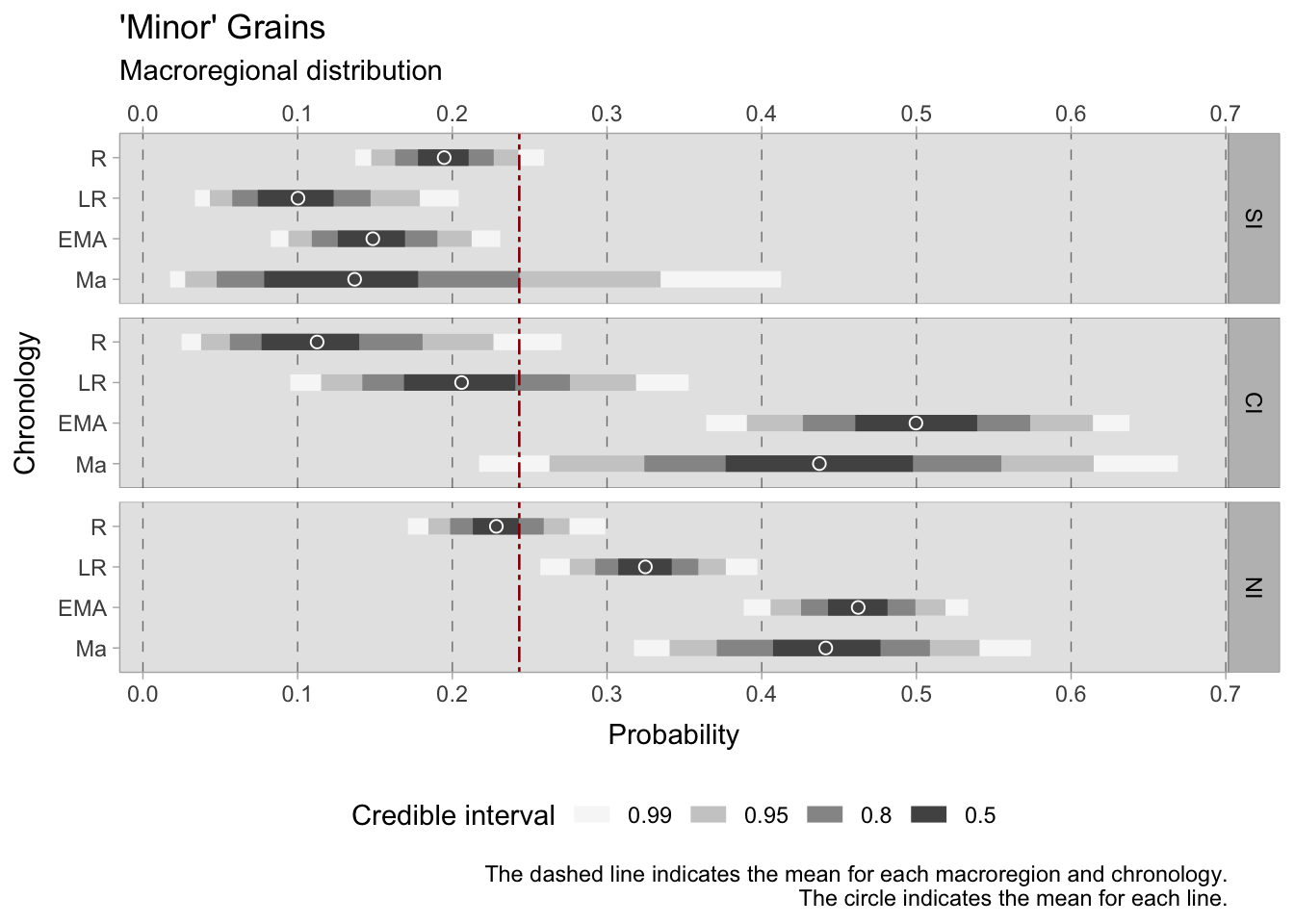
7.4.1.3 Cereal richness in the Italian macroregions
In Section 6.3.4, detailed insights into the pre-processing of archaeobotanical data were provided, aiming to enhance the accuracy of cereal richness estimates across the three distinct Italian sub-regions. The original group sizes before this pre-processing are illustrated in Table 7.2, while Table 7.3 displays the reduced number of samples following the data processing steps. For a more granular view of the impact of data processing, Table 7.4 presents the effective count of caryopses per group, with the mean richness conveniently summarised in Table 7.5. Examining cereal presence values reveals similarities between Roman northern and southern Italian sites. Notably, central Italy reports higher values, albeit caution is warranted as this observation relies on data from only three sites, rendering it less reliable. Transitioning to the early Middle Ages, central Italy emerges once again as the region richest in cereals, closely trailed by northern Italy. A particularly interesting observation is the continuing similarity of cereal values in southern Italy, which remain remarkably close to those recorded in Roman times. For a comprehensive listing of southern Italian early Middle Ages sites, refer to Table 7.6.
| Chronology | Northern Italy | Central Italy | Southern Italy |
|---|---|---|---|
| Roman | 43 | 5 | 35 |
| Late Roman | 46 | 8 | 10 |
| Early Medieval | 42 | 10 | 17 |
| 11th c. | 12 | 4 | 2 |
| Chronology | Northern Italy | Central Italy | Southern Italy |
|---|---|---|---|
| Roman | 36 | 3 | 27 |
| Late Roman | 42 | 5 | 5 |
| Early Medieval | 39 | 10 | 13 |
| 11th c. | 12 | 4 | 1 |
| Chronology | Northern Italy | Central Italy | Southern Italy |
|---|---|---|---|
| Roman | 44483 | 164 | 28401 |
| Late Roman | 422183 | 8328 | 241 |
| Early Medieval | 473423 | 104556 | 15065 |
| 11th c. | 46764 | 37148 | 352 |
| Chronology | Northern Italy | Central Italy | Southern Italy |
|---|---|---|---|
| Roman | 2.94 | 1.67 | 2.93 |
| Late Roman | 3.76 | 3.40 | 2.60 |
| Early Medieval | 5.26 | 5.50 | 2.85 |
| 11th c. | 4.67 | 5.00 | 3.00 |
| ID | Site | Region | Geography | Type | Culture/Influence |
|---|---|---|---|---|---|
| 98 | S. Maria in Cività, D85 | Molise | Hilltop | Urban | Lombard |
| 107 | S. Giovanni di Ruoti, Phase 3A | Basilicata | Mountain | Monastery | Lombard |
| 107 | S. Giovanni di Ruoti, Phase 3B | Basilicata | Mountain | Monastery | Lombard |
| 198 | Salapia, area botteghe, US 2475 | Puglia | Coast/Lagoon | Urban | Lombard |
| 198 | Salapia, area botteghe, US 2437 | Puglia | Coast/Lagoon | Urban | Lombard |
| 199 | Salapia, area conceria, US 2054 | Puglia | Coast/Lagoon | Urban | Lombard |
| 199 | Salapia, area conceria, US 2211-2217 | Puglia | Coast/Lagoon | Urban | Lombard |
| 199 | Salapia, area conceria, 8th-9th c. | Puglia | Coast/Lagoon | Urban | Lombard |
| 196 | Faragola, wastepit 61 | Puglia | Plain | Rural, villa | Lombard |
| 196 | Faragola, wastepit 66 | Puglia | Plain | Rural, villa | Lombard |
| 234 | Colle Castellano, Phase 3-4 | Molise | Hill | Urban | Lombard |
| 177 | San Vincenzo al Volturno, kitchen area | Molise | Hill | Monastery | Lombard |
| 101 | Supersano, loc. Scorpo | Puglia | Plain | Rural | Byzantine |
| 250 | Apigliano, 9th-10th c., pits | Puglia | Plain | Rural | Byzantine |
| 250 | Apigliano, 10th-11th c., pits | Puglia | Plain | Rural | Byzantine |
| 196 | Faragola, granary A7 | Puglia | Plain | Rural, villa | Lombard |
| 196 | Faragola, granary A8 | Puglia | Plain | Rural, villa | Lombard |
7.4.1.4 Assessing the difference
In order to substantiate the proposed shift in cereal farming during the early medieval period, as discussed in both Section 7.1.1 and Section 7.4.1.3, statistical validation is needed. Given the non-unimodal nature of the data and the use of presence/absence analysis, a robust choice is the application of a non-parametric test, such as PERMANOVA, on the early medieval botanical dataset. Before subjecting the data to the PERMANOVA analysis, we pre-processed it as outlined in Section 6.3.4. To establish a baseline for comparison, the same PERMANOVA procedure was applied to the Roman dataset.
The code snippet provided below demonstrates the utilisation of the adonis2() function to perform the PERMANOVA calculation:
# Example of how to use the function adonis()
1set.seed(29)
Permanova.Cereals.R = adonis2(
2 Bot_PA_data.R ~ Macroregion,
data = Bot_PA_categ.R,
3 permutations = 10000,
4 method="jaccard"
)- 1
- In order to get the same results, we set a seed.
- 2
- Formula specification.
- 3
- Number of random permutations.
- 4
- Distance metric.
| Phase | R2 | p-value |
|---|---|---|
| Roman | 0.03 | 0.0977902 |
| Early Medieval | 0.10 | 0.0001000 |
PERMANOVA analysis was performed on the Roman dataset using the variable Macroregion, indicating a lack of statistical significance in the calculated p-value, implying homogeneity in the dataset. However, the early medieval dataset showed highly significant results (0<p<0.001) with 99.99% confidence. Due to insufficient samples from southern Italy, PERMANOVA was not conducted on the late Roman dataset. To verify the statistical significance of the PERMANOVA outcomes obtained using the EMA dataset, it is critical to ensure that the underlying assumptions are fulfilled, especially given our small group sizes. We first examine the homogeneity of variances, determining the distances between group samples and centroids using the betadisper() function in the vegan package. If the variance is consistent, we accept the null hypothesis of no variation in dispersion between groups. To assess variance, we can employ analysis of variance (ANOVA).
| Phase | Northern Italy | Southern Italy |
|---|---|---|
| Roman | 0.53 | 0.48 |
| Early Medieval | 0.37 | 0.38 |
| Phase | p-value |
|---|---|
| Roman | 0.1892284 |
| Early Medieval | 0.9374030 |
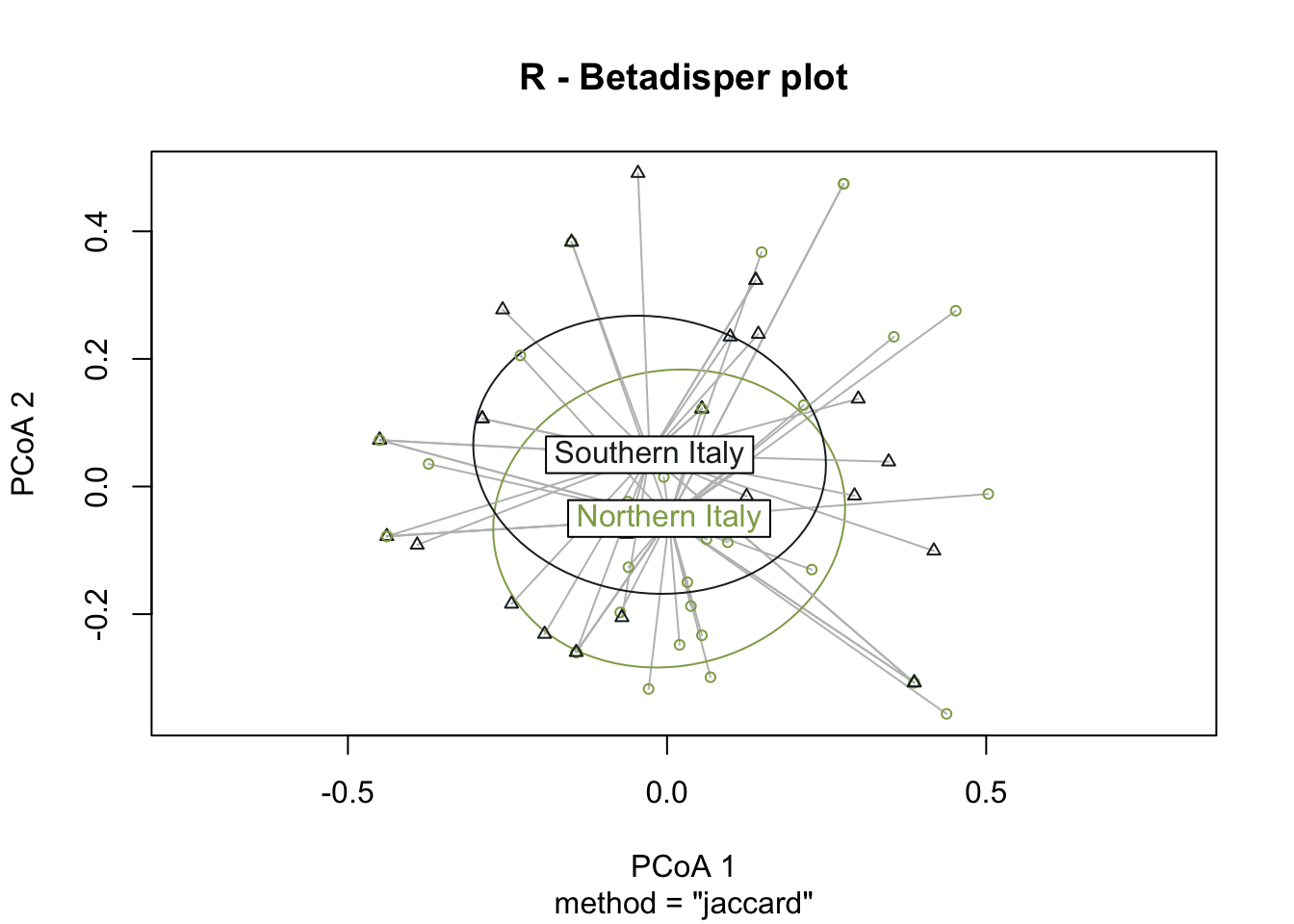
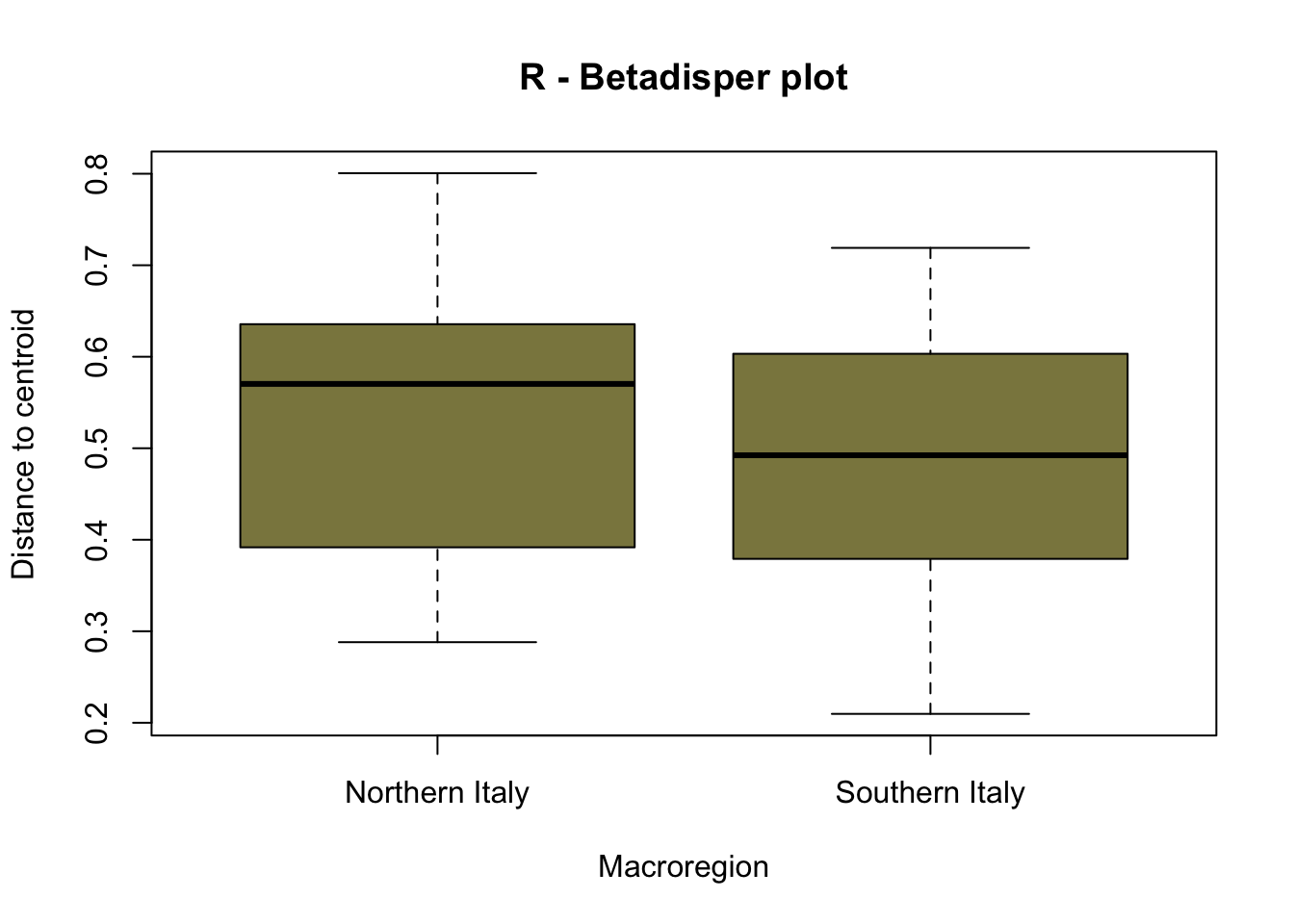
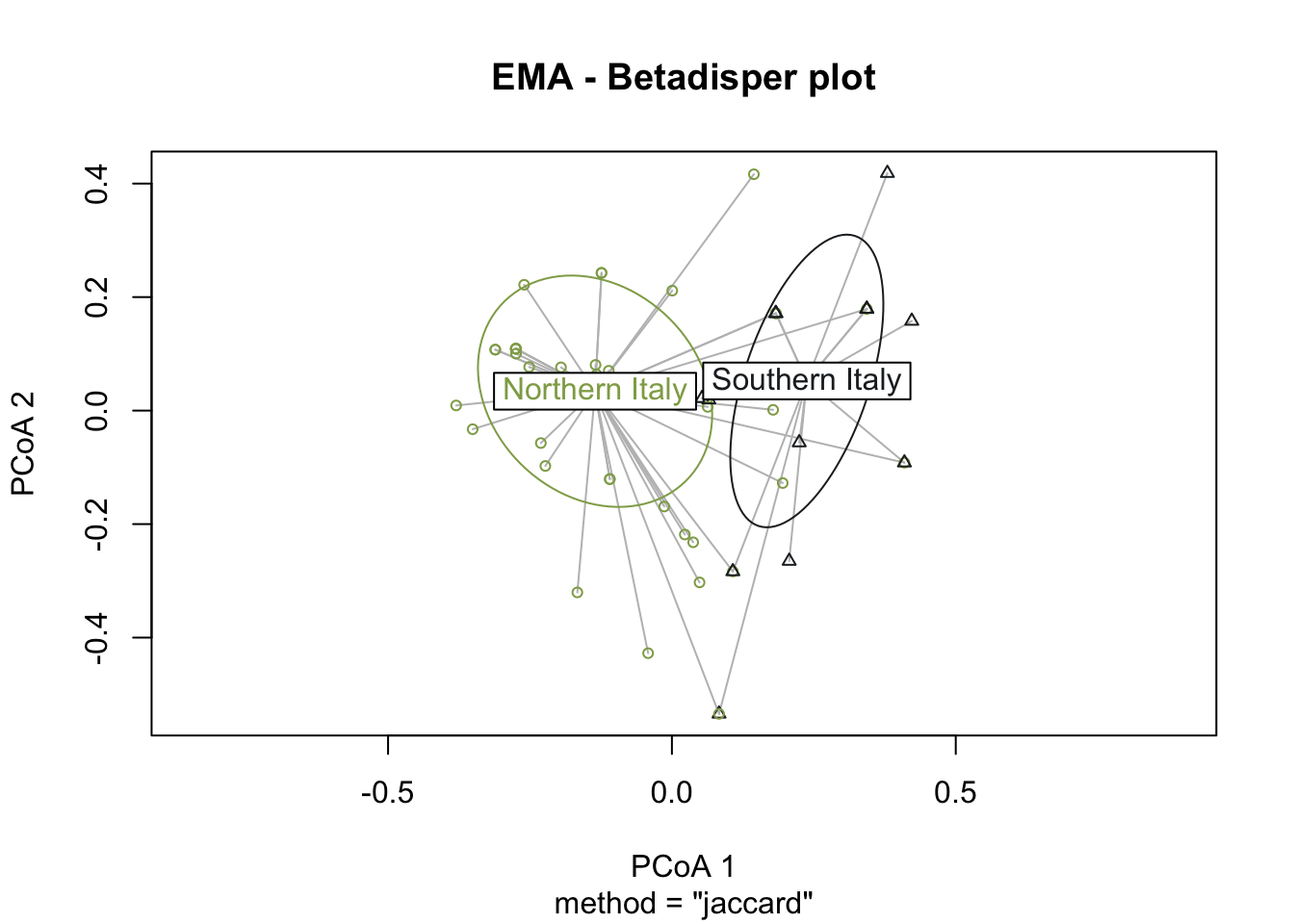
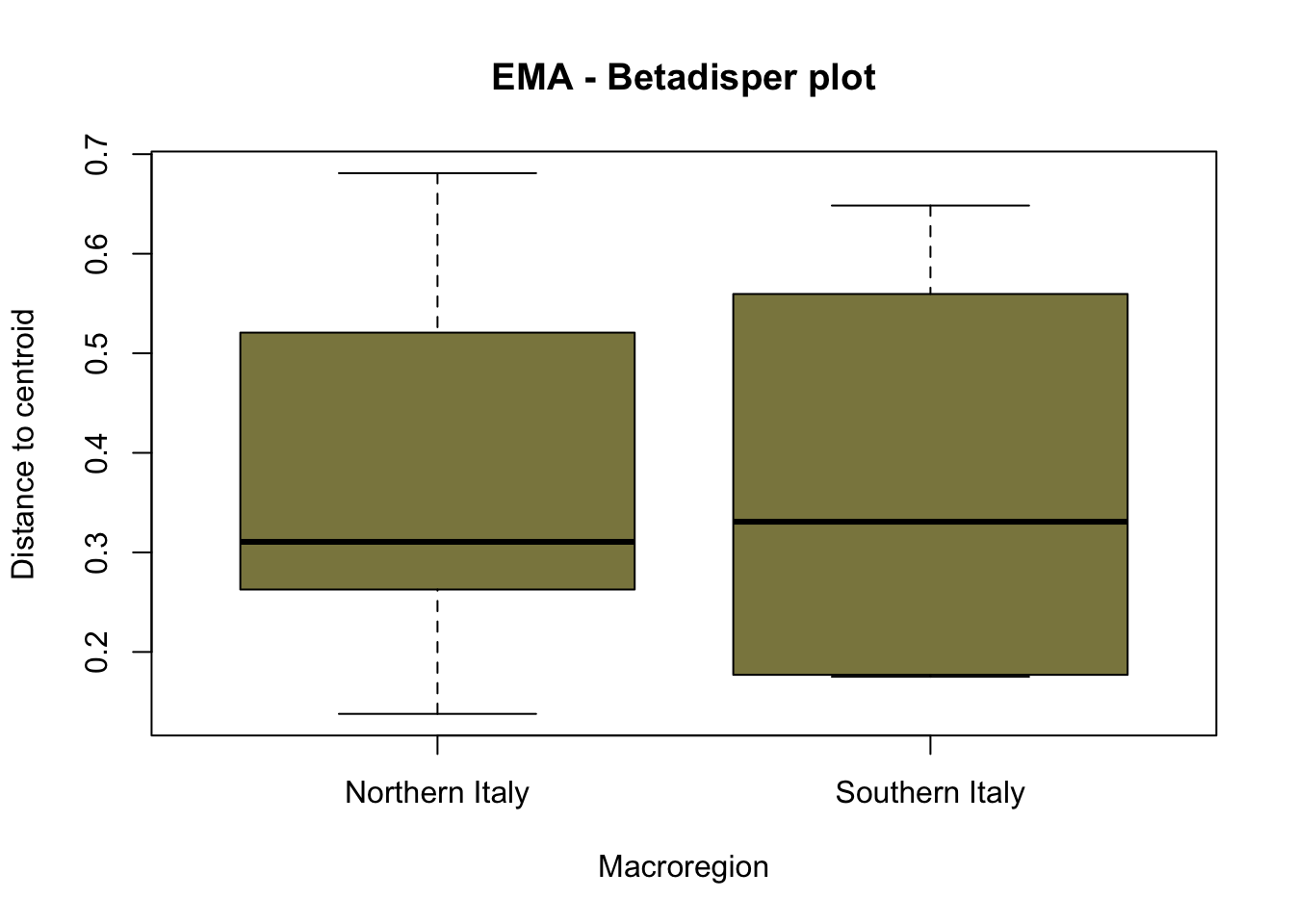
The graphical representation through betadisper() plots (Figure 7.16) illustrates a comparable distance from centroids for both northern Italy and southern Italy categories. Complementing this visual analysis, the ANOVA on betadisper() affirms the lack of significance (p-value exceeding the threshold), indicating homogeneity in group dispersions (Table 7.9). This robust statistical foundation leads us to confidently affirm the results obtained from the PERMANOVA analysis, supporting the conclusion that there is a significant difference between the two groups of sites—southern and northern Italy—specifically in the realm of cereal farming during the early Middle Ages.
Conversely, when the same tests were applied to Roman sites, the outcomes failed to delineate a significant separation between the two groups. This corroborates the notion that, during the Roman age, there was not a noteworthy difference in the types of cereals cultivated between northern and southern Italy.
7.4.1.5 Quantifying the separation: nMDS
In the investigation of the northern and southern Italian early medieval cereals dataset (Section 7.4.1.4), an additional approach involves quantifying the distance between groups of sites for both the Roman and early Middle Ages. For this purpose, the chosen dimensionality reduction algorithm is the non-metric multidimensional scaling (nMDS) available in the vegan library for R. A detailed explanation of this algorithm is provided in Section 6.3.3.2.1. The code snippet below exemplifies the utilisation of the metaMDS() function to perform the nMDS.
- 1
- We set a seed as these computations are random.
- 2
- Dataframe on which to perform the nMDS.
- 3
- Set the number of dimensions to 1.
- 4
- Distance metric.
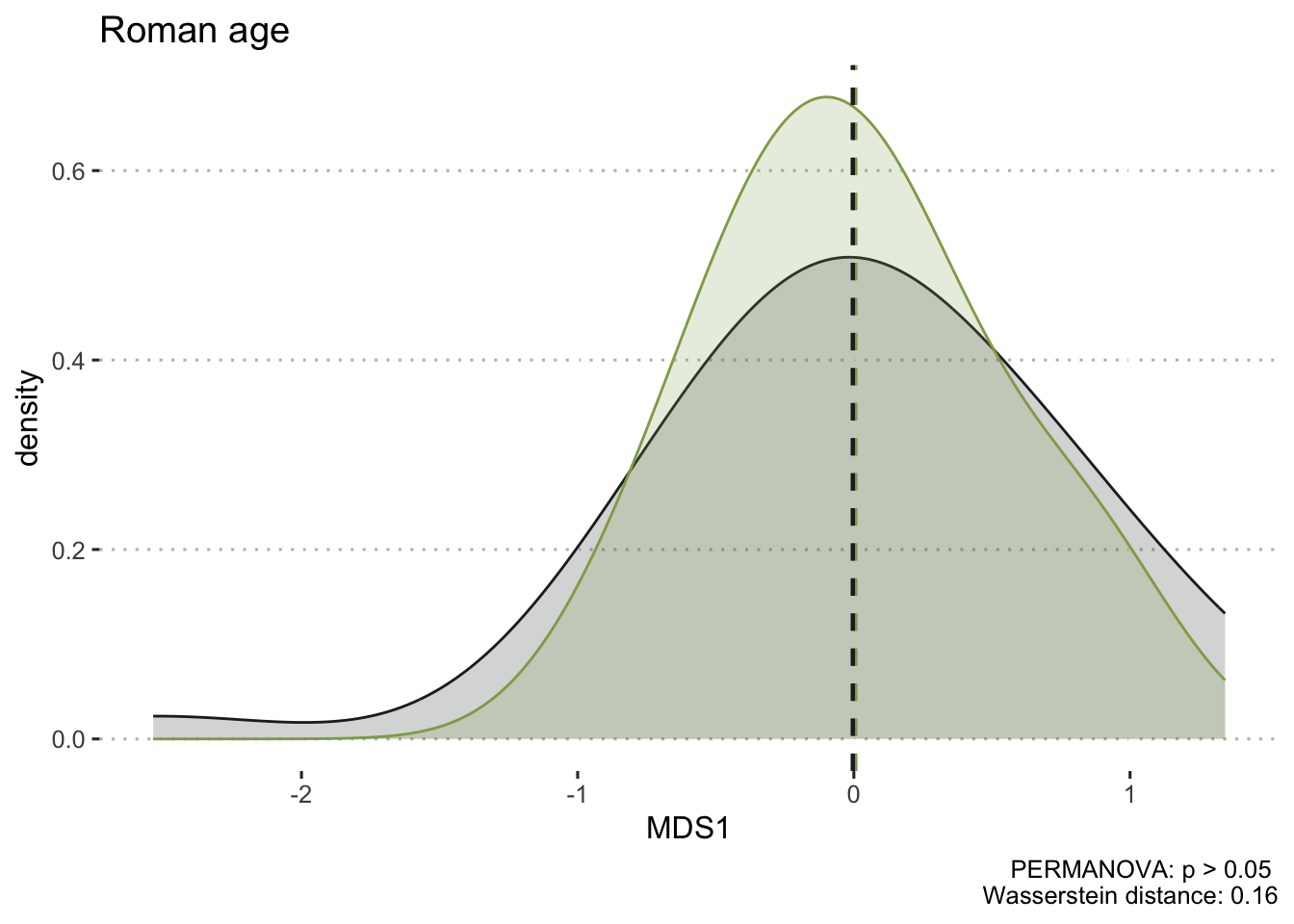
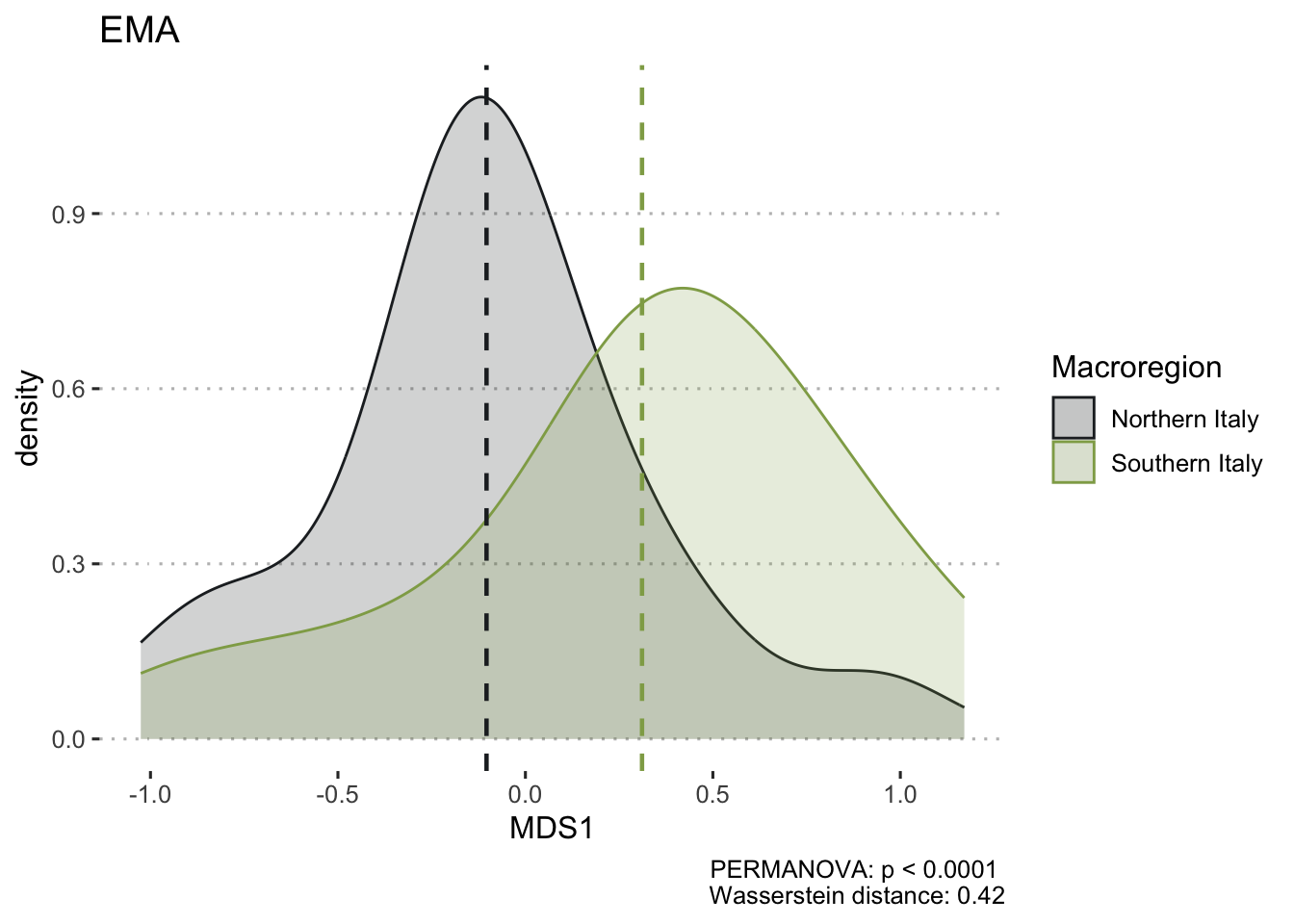
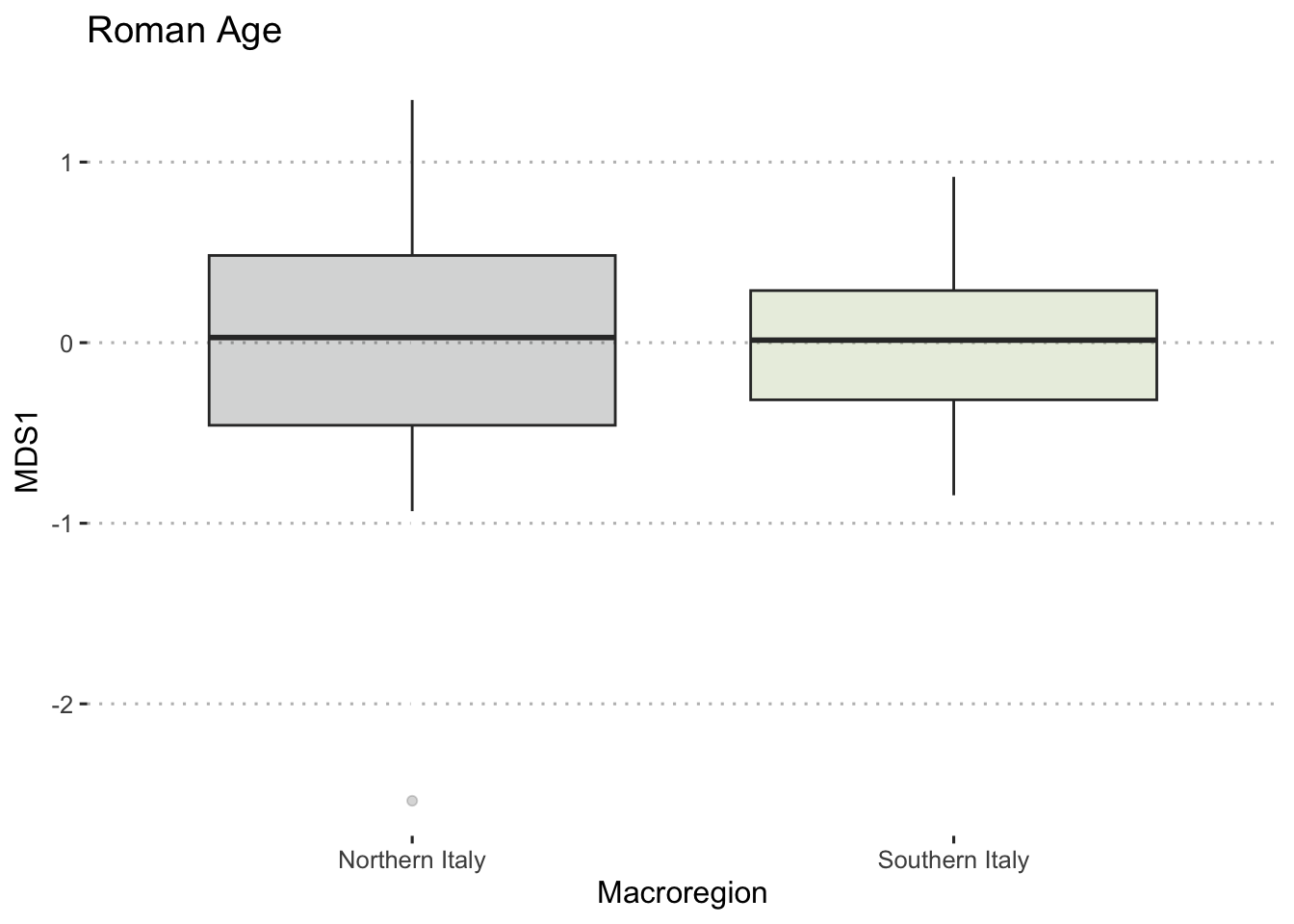
To ensure the integrity of computations and avoid potential fallacies, the macroregion central Italy and the chronologies LR (late Roman) and Ma (11th century onwards) have been excluded from this analysis. This cautious approach is taken due to the uneven distribution of the group of samples. The nMDS has reduced the cereal dataset to a single dimension, both for effective visualisation of the results with KDE plots and to facilitate distance calculations. In Figure 7.17 (a), the nMDS results for the Roman cereals presence/absence dataset are presented. As previously highlighted, the non-significant outcome of the PERMANOVA aligns with the shorter Wasserstein distance, as calculated using the wasserstein1d() function from the transport library. Both chronologies exhibit an overlap in the curves, with the Roman age displaying a more substantial overlap, indicative of higher similarity within the group of assemblages. The EMA groups’ overlap (Figure 7.17, b) can be attributed to the fact that the presence of free-threshing wheats and barley is not exclusive to southern Italian sites; these grains are prevalent in the north as well. The key distinction lies in the south, where ‘noble’ grains are not cultivated in tandem with other grains. The graph for the EMA chronology reveals a clearer separation of macroregional groups, with minor overlaps. Additionally, the graph highlights variability in the northern Italian dataset, a characteristic further underscored by outliers in the boxplots in Figure 7.17.
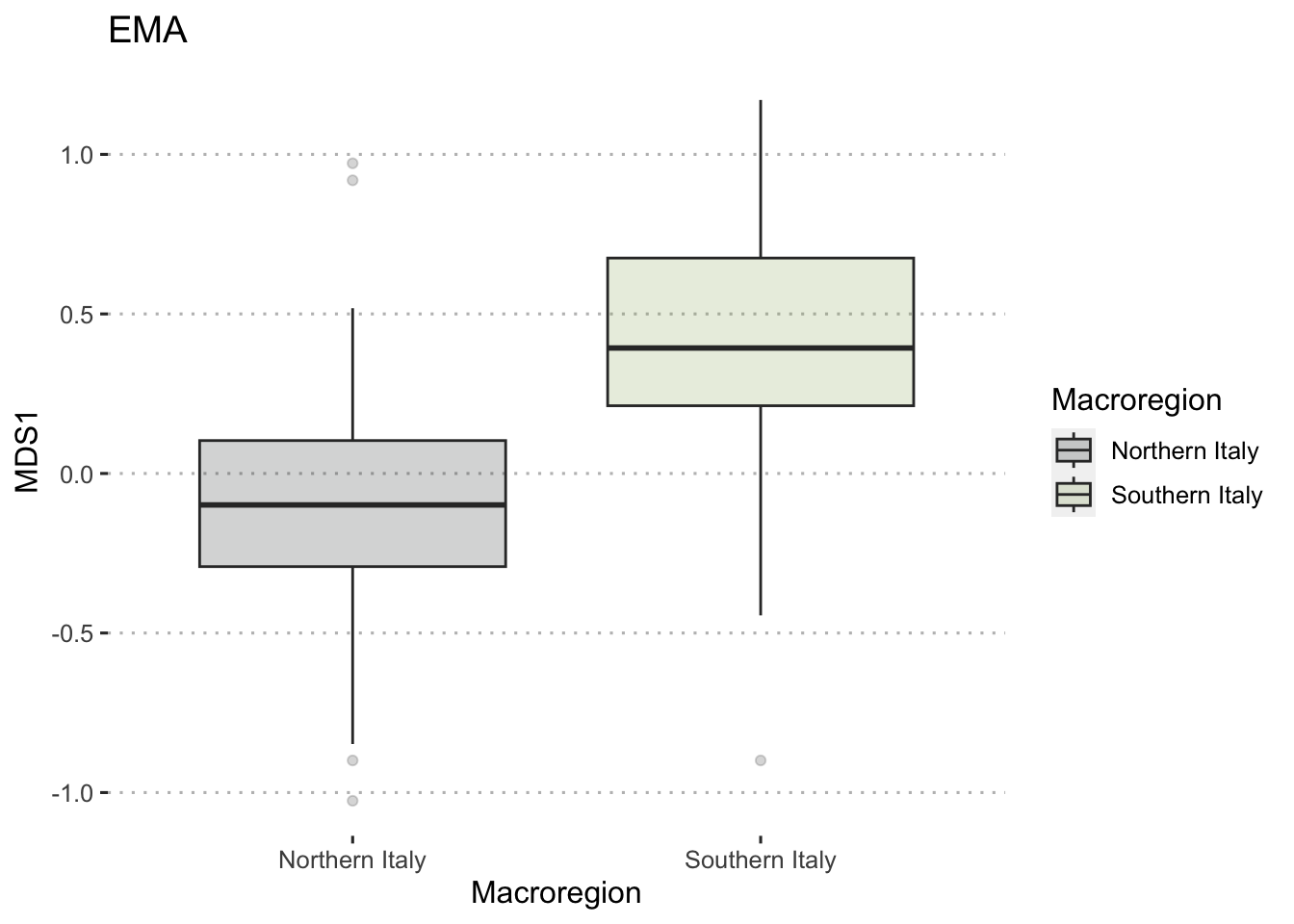
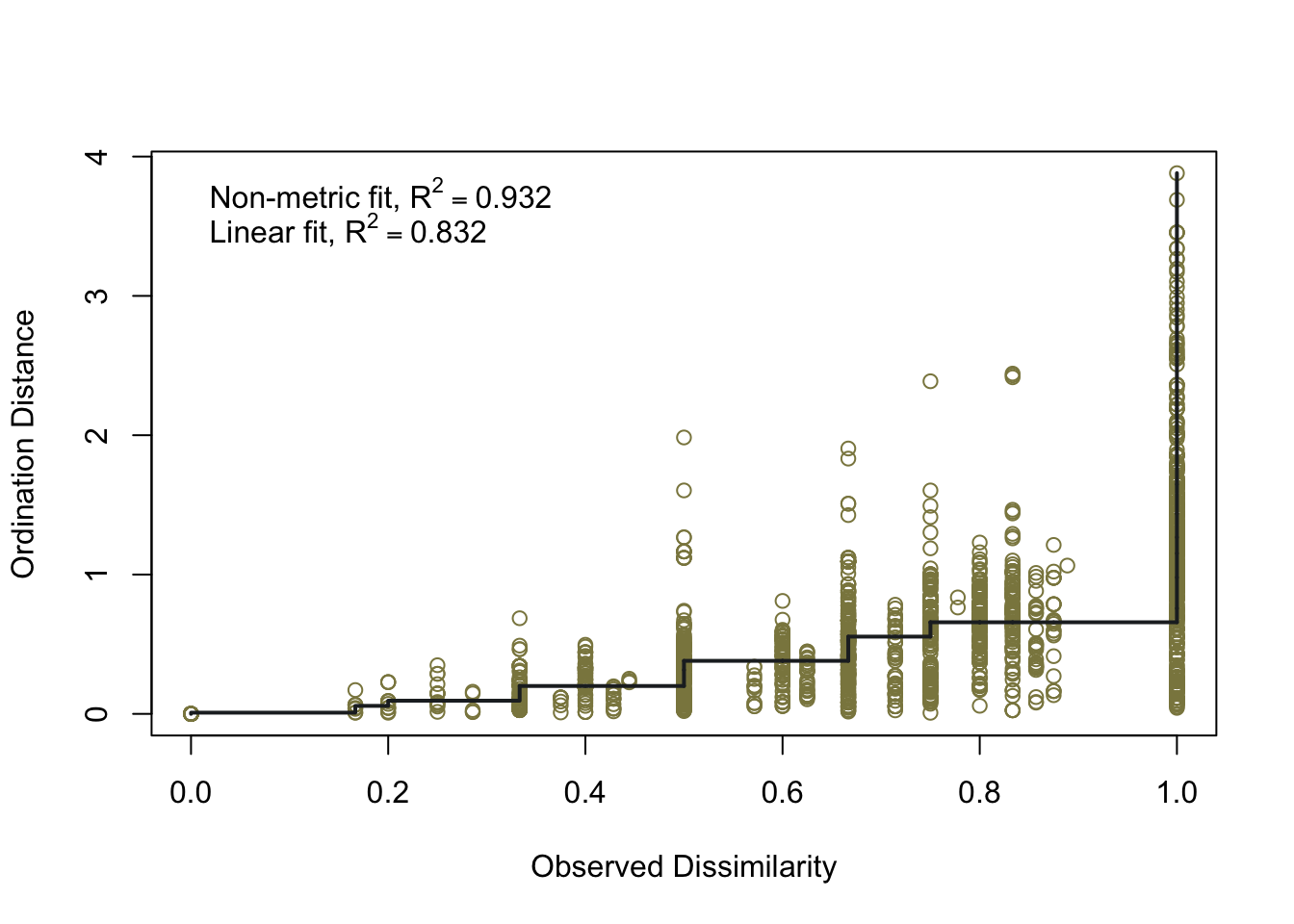
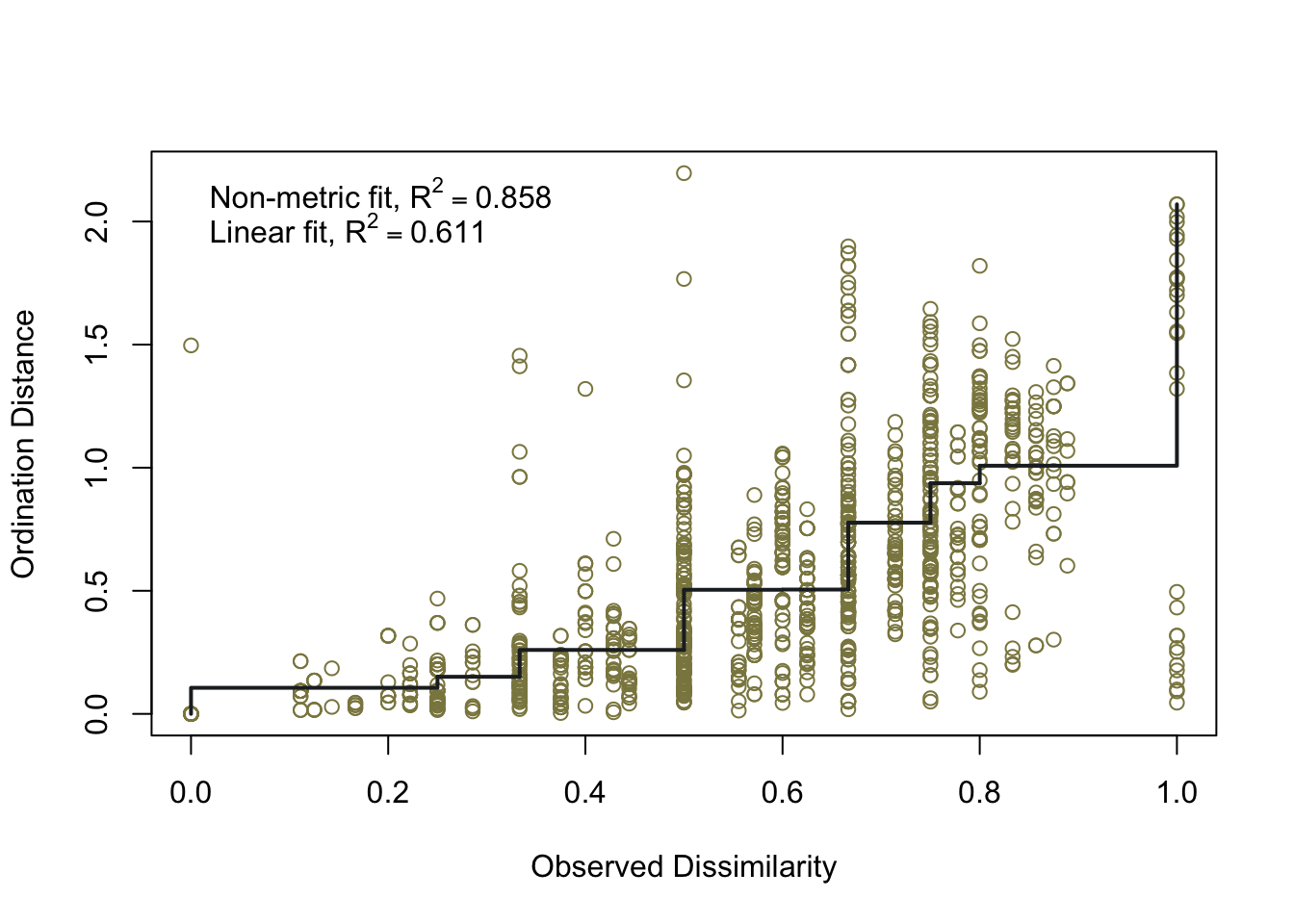
7.4.2 Legumes
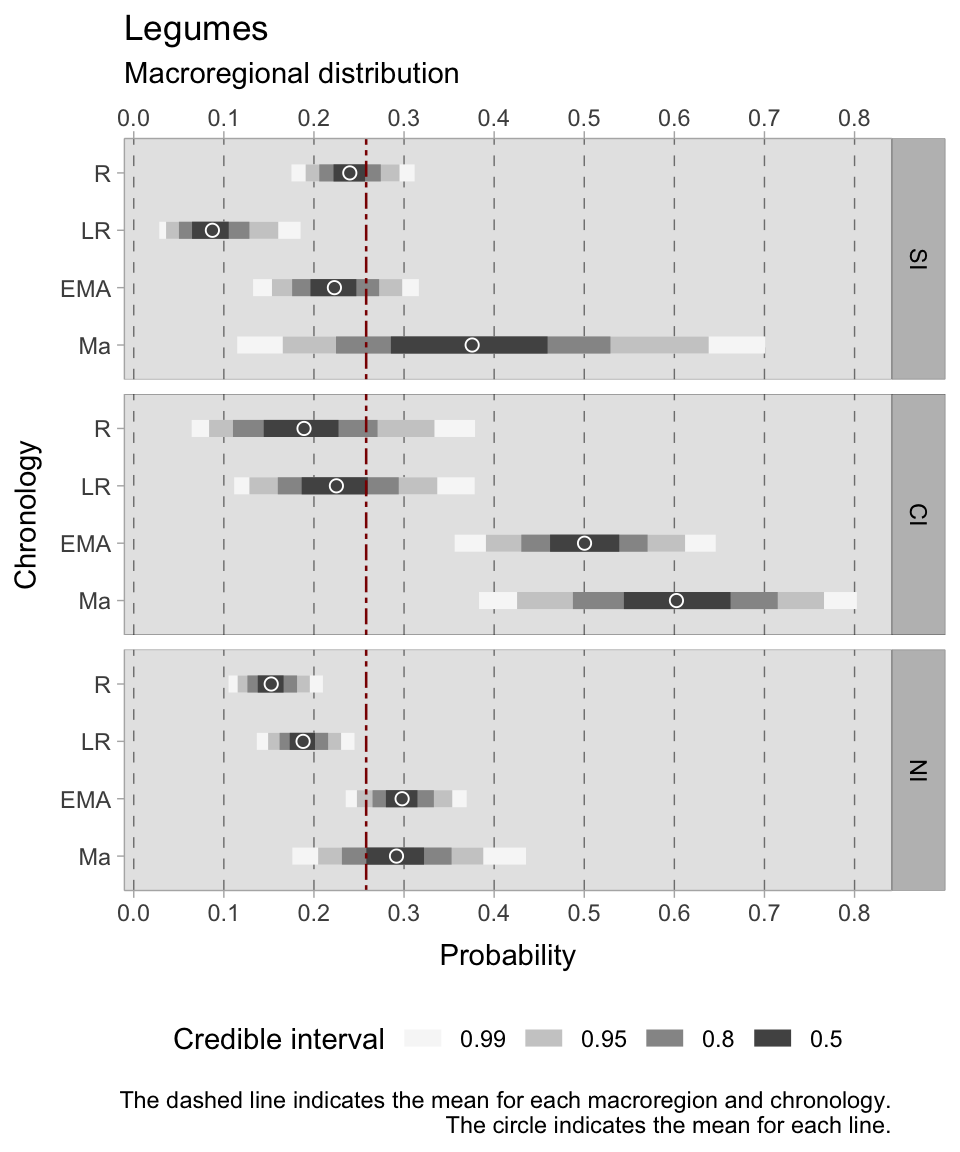
After a comprehensive study of the presence and abundance of cereals, we now turn our attention to the study of the distribution of legumes in the three Italian sub-regions, stratified chronologically. We will not go into the technical details of constructing this multi-level model, as the methodology is the same as that described above for cereals, using identical predictors and priors. A clear trend is illustrated in the accompanying figure (Figure 7.19).
Northern Italy consistently shows the most reliable credible intervals in each chronology, with southern Italy (except for the 11th century samples) following closely. Conversely, central Italy has wider ranges, indicating greater uncertainty in the estimates. From the Roman period (mean = 0.15) to the early medieval and medieval periods (means = 0.30/0.29), the estimated means increase in the north. From the Roman (mean = 0.24) to the late Roman (mean = 0.09) period, there is a marked decrease in southern Italy, followed by an increase during the early medieval (mean = 0.23) and medieval periods (mean = 0.37, but with an HDI varying between 0.29 and 0.46). Similarly, the central Italian area shows a steady increase in the cultivation of legumes, with a mean of 0.19 in the Roman phase and peaking at 0.60 in the 11th century samples (but with a credible interval of 0.50 ranging from 0.55-0.66). The importance of legumes in this sub-region aligns with expectations, considering the hilly landscape and the historical agricultural focus of this area.
7.4.3 Fruits
Binomial models have been systematically developed for a number of fruit categories, following the same methodological approach as other macro-regional models and using the same priors. The specific formulae of the models are not repeated here, but they follow the established methodology.
The results for the two main cash crops, grapes and olives, are of particular interest. The analysis shows considerable variability in the results for these crops, indicating a degree of uncertainty in the estimates. The scope of our investigation is not limited to marketable crops, as we have also assessed the diversity of wild and domestic fruits and nuts, providing an in-depth study of heterogeneous fruit categories in different Italian sub-regions and over different time periods.
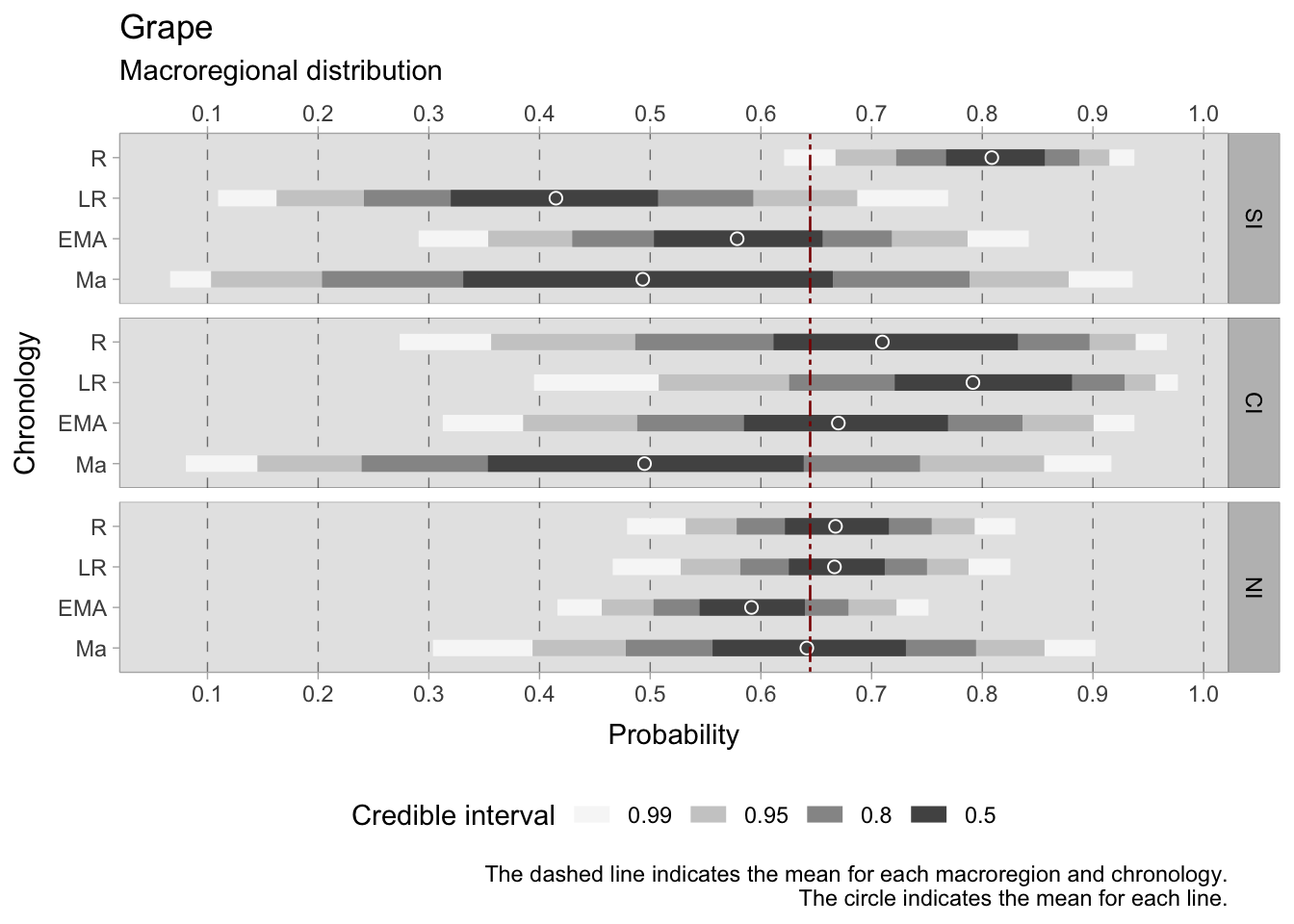
7.4.3.1 Grape
The models assessing the occurrence of grapes exhibit notable dispersion, leading to large credible intervals. Basing our interpretation on the 0.50 HDIs, in the Roman period, grapes were markedly more prevalent in the southern regions (0.76-0.85), aligning with expectations given their warmer climates and longstanding tradition of grape cultivation. Central Italy also displayed widespread cultivation, albeit with a larger interval (0.61-0.82). The north showed a notable presence as well, with an HDI ranging between 0.62-0.72. However, in the late Roman period, credible intervals expanded significantly, especially in southern and central Italy. In the south, there was a substantial decrease in the HDI ranges, ranging between 0.32 and 0.50. Contrastingly, central Italy displayed a HDI in a higher probability range, spanning between 0.72-0.86. In the north, the range remained similar to the previous phase, with an estimated mean around the overall mean of 0.65.
Transitioning to the early medieval phase, the occurrence of grapes experienced a renewed increase in the south (range: 0.50-0.65). However, central Italy and the north witnessed a decline in their HDIs. Particularly in northern Italian assemblages, the estimated mean (0.60) dropped below the Roman maximum of 0.66. Notably, the north demonstrated minimal variation in means across the four phases, with the 11th-century samples returning a mean of 0.65. In southern and central Italy, broad credible intervals limit the provision of valuable information.
7.4.3.2 Olives
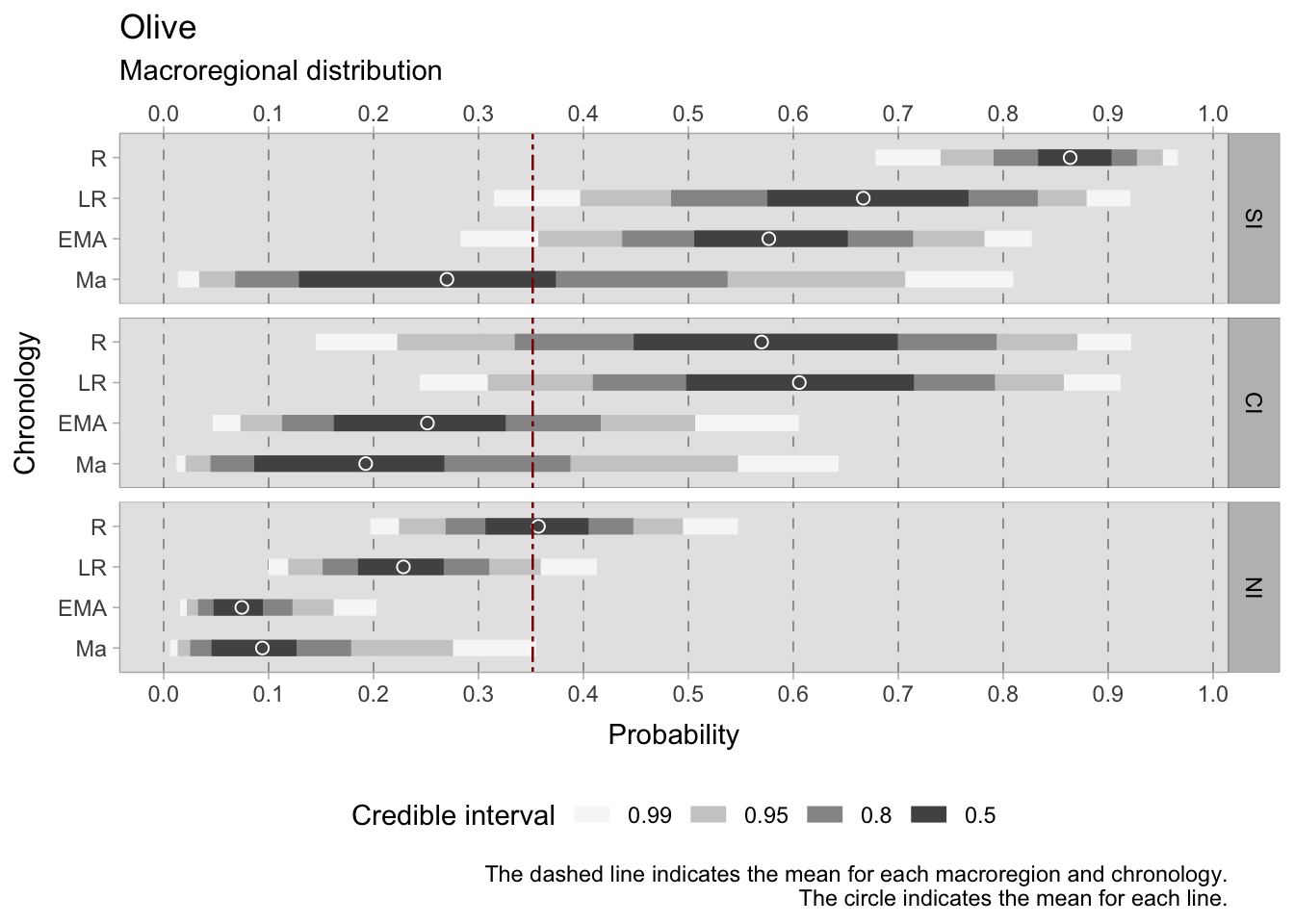
As with grapes, the models for olive occurrence show credible intervals of considerable size, which presents a challenge to reliable interpretation. When the 0.50 HDIs are used to gain insight, discernible trends emerge. In particular, there is a marked difference between the south and the north of Italy, which is mainly due to climatic factors, as will be explained in more detail in the following models in this chapter. In the Roman period, the HDI for the south lies between 0.83 and 0.90, underlining the strong presence of olives. In contrast, the north has a much lower HDI of 0.30-0.40, reflecting less widespread cultivation. The paucity of sites in Roman central Italy results in a wide 0.50 HDI (0.46-0.70), and the 0.99 HDI for this region is exceptionally scattered (0.12-0.91), making it unreliable. During the late Roman period, the HDIs remain wide, especially for the southern (0.59-0.77) and central (0.50-0.71) regions. However, in the North, the range tightens to 0.19-0.25, suggesting a more consistent pattern. As we approach the early medieval period, the presence of olives diminishes in all regions, with the HDI ranging from 0.50-0.65 in the south, 0.17-0.31 in the centre and 0.05-0.1 in the north, where the dataset is more coherent and substantial. The falling continues in the samples after the 11th century, although this period shows increased variability between sites.
7.4.3.3 Nuts
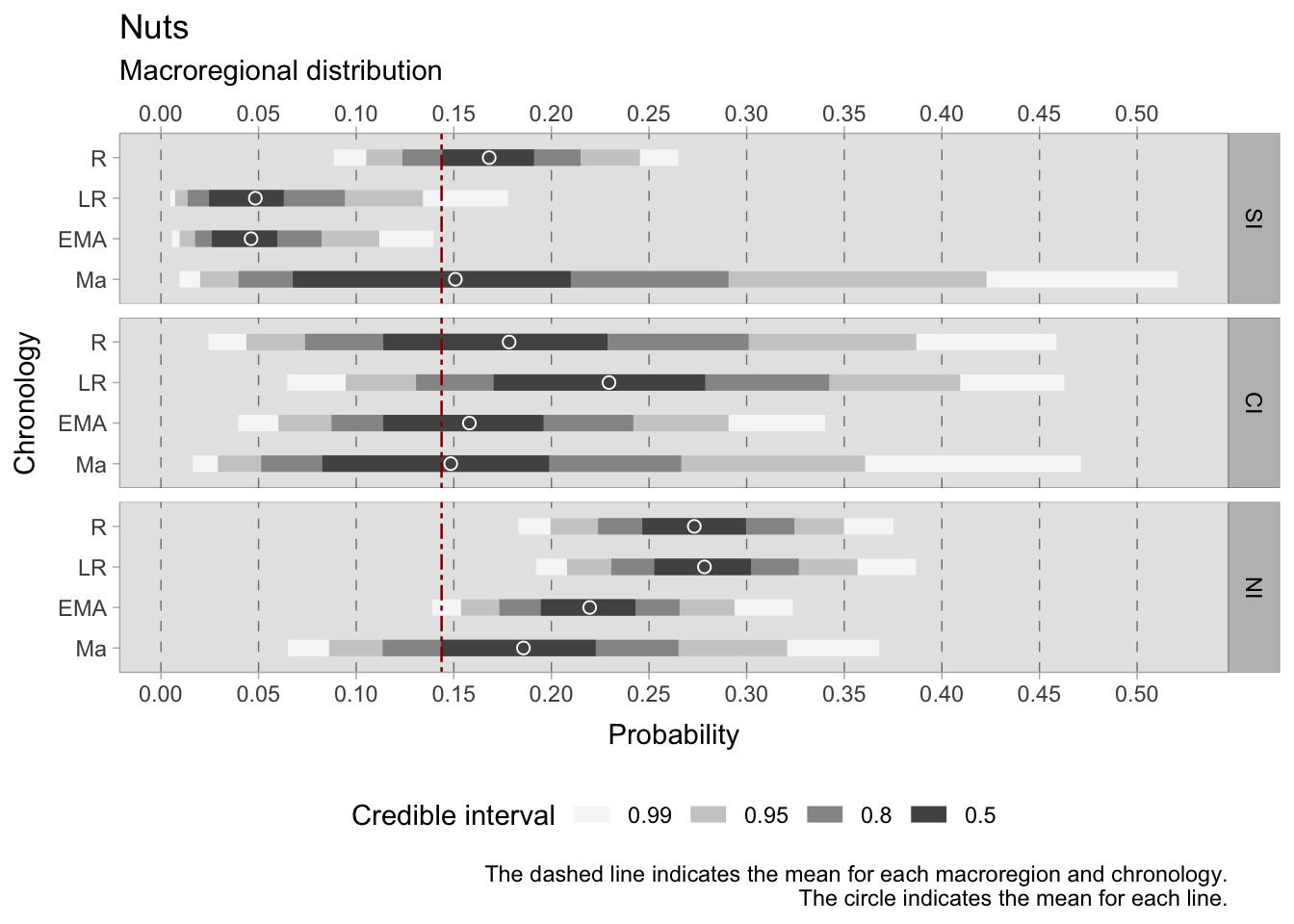
The examination of archaeobotanical remains of nuts reveals minimal variations across regions and chronological phases. During the Roman period, nuts were estimated to occur in the southern regions at a frequency of between 0.14 and 0.19. However, interpreting the data for central Italy is challenging due to a large credible interval. In the highest density region, the estimated frequency ranges from 0.11 to 0.26, indicating substantial uncertainty in the estimates. In the northern regions, the estimated occurrence is relatively narrower, ranging from 0.24 to 0.30.
During the late Roman period, the presence of nuts declines in the southern regions, with the estimated range dropping to between 0.03 and 0.06. In central Italy, a broad credible interval persists, ranging from 0.17 to 0.28. Meanwhile, the estimated range in the northern regions remains similar to that observed in the Roman phase, hovering between 0.25 and 0.30.
In the early medieval period, nuts continued to be present in the south, maintaining a level of consistency similar to that of the late Roman phase. In central Italy, the estimated range shifts to 0.11 to 0.19. Northern Italy reports an estimated range of 0.19 to 0.24, suggesting a slight fluctuation.
The southern and central regions have very large credible intervals in the 11th century, rendering the estimates less reliable. However, the estimated mean closely aligns with the overall mean of 0.15 in both regions. In contrast, the north reports an estimated range of 0.14 to 0.23, indicating a continued presence of nuts during this period.
7.4.3.4 Domestic and wild fruits
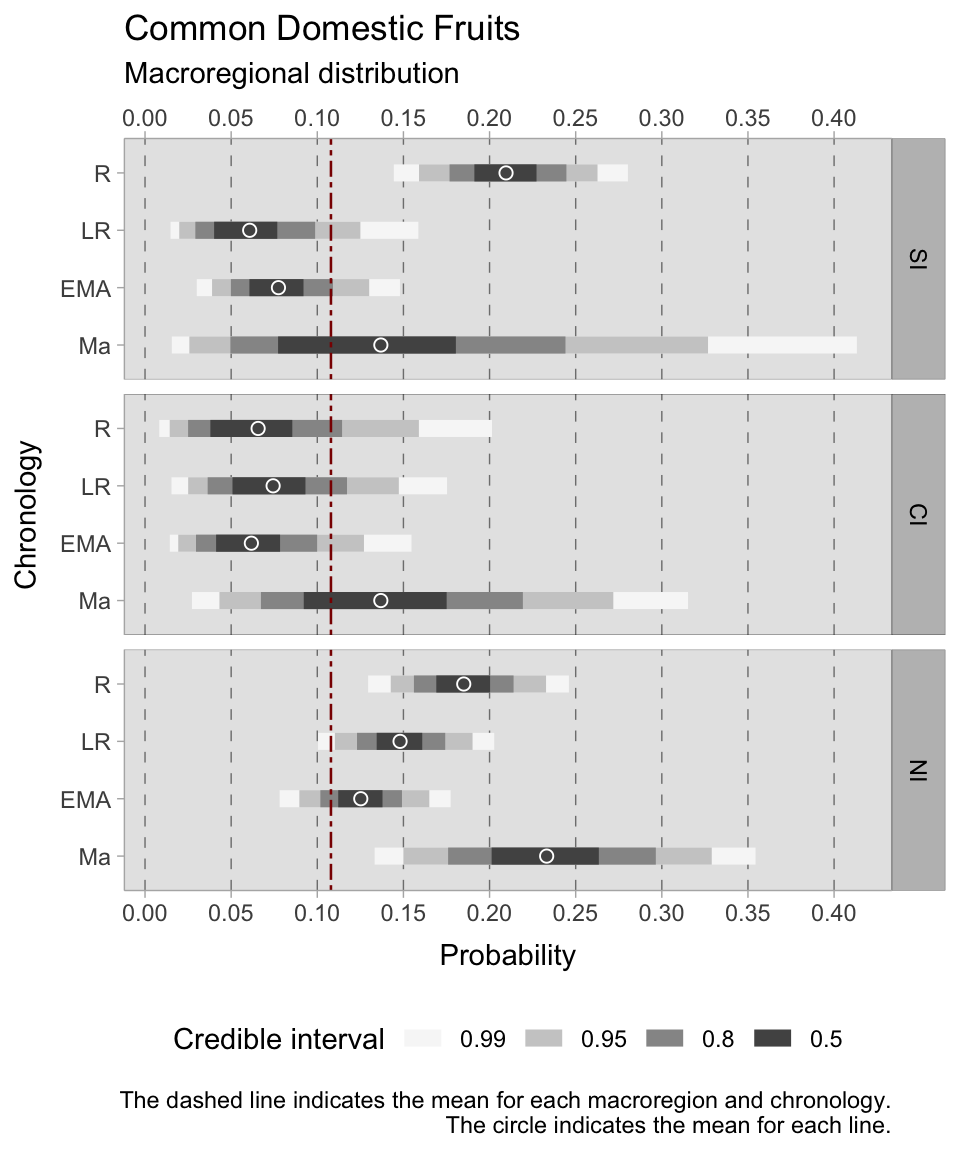
The model for domestic fruit occurrence outperformed previous fruit models. During the Roman period in southern Italy, the probability of domestic fruit presence ranged from 0.19 to 0.24 with a 0.50 credible interval. In Roman central Italy, estimates suggest a more modest presence of domestic fruit, ranging from 0.03 to 0.07.
In the late Roman era, domestic fruit occurrence declined in the southern regions, estimated to be between 0.04 and 0.07. However, there was a mild improvement in domestic fruit presence in the late Roman centre, estimated to range from 0.05 to 0.09. The north sustained a similar range as the previous phase, which was between 0.14-0.16.
In the early medieval period, the southern regions continue to show the presence of domestic fruit, ranging from 0.06 to 0.09. The early medieval centre shows a similar presence, with estimates ranging from 0.04 to 0.07. In the northern region, the presence of domestic fruit is reported, with estimates ranging from 0.12 to 0.14. Until the 11th century, the south maintains its presence of domestic fruit, estimated between 0.07 and 0.17. In central Italy there is also a continued presence, with estimates between 0.09 and 0.17. In the north, a significant presence of domestic fruit is observed, with estimates ranging from 0.20 to 0.26. It is worth noting that the higher HDIs in this phase are due to a smaller number of observations, thereby introducing increased uncertainty.
The model for less commonly domesticated and (mainly) wild fruits shows a low dietary impact of these fruits during the 1st millennium CE. There is a noticeable trend, with southern and central Italy showing lower HDIs, falling below the mean of 0.07 from the Roman to the early medieval period. Reliable results, attributed to tighter HDIs, show a consistent range between 0.09 and 0.16. The small presence observed in this area is in contrast to the consumption pattern observed in northern Italy. Upon further investigation into the 11th century, a clear increase in the presence of berries can be seen across all sub-regions. In the south, HDIs increase from 0.03 to 0.09, reflecting a higher density of findings of less commonly domesticated fruits. Central Italy shows an increase in the prevalence of these fruits, reaching HDI values between 0.07 and 0.14. In contrast, northern Italy experiences the largest growth, with HDI values peaking between 0.27 and 0.34, indicative of a substantial rise in the utilisation of berries and other fruits during this period.
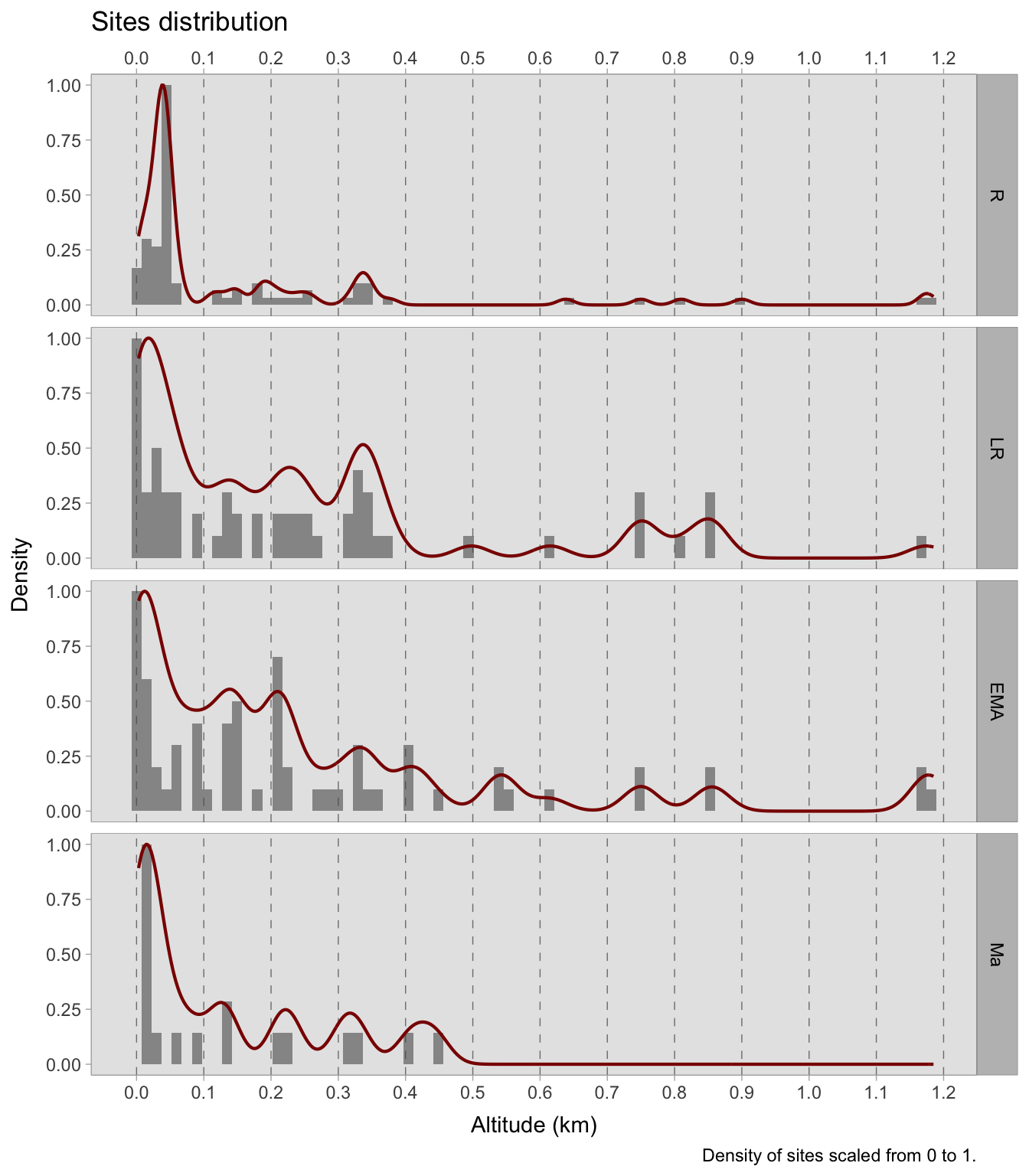
7.5 Altitude
The probability of the occurrence of the most prevalent cereal remains can be modelled against site elevation in the four time periods examined. The distribution of archaeobotanical remains across sites is uneven. During the Roman age, the majority of investigated sites are situated between 0 and 100 MSL. However, there is a rise in the number of sites at higher elevations in the subsequent phases. Though this may indicate a change in settlement patterns, it is not the focus of this study. Nonetheless, mapping the distribution of sites according to elevation could yield valuable information. Due to the time consuming nature of the process, it was not possible to produce elevation models for all the plants surveyed. Therefore, we selected only those plants that showed susceptibility to altitude-based positive or negative effects or were economically significant. Cereal crops were given priority. As not all cereals are suitable for cultivation at high altitudes, it was considered more appropriate to model them independently instead of categorising them into ‘noble’ and ‘minor’ grains. For reference, the breakdown of site elevations studied during the four chronologies can be found in Figure 7.25.
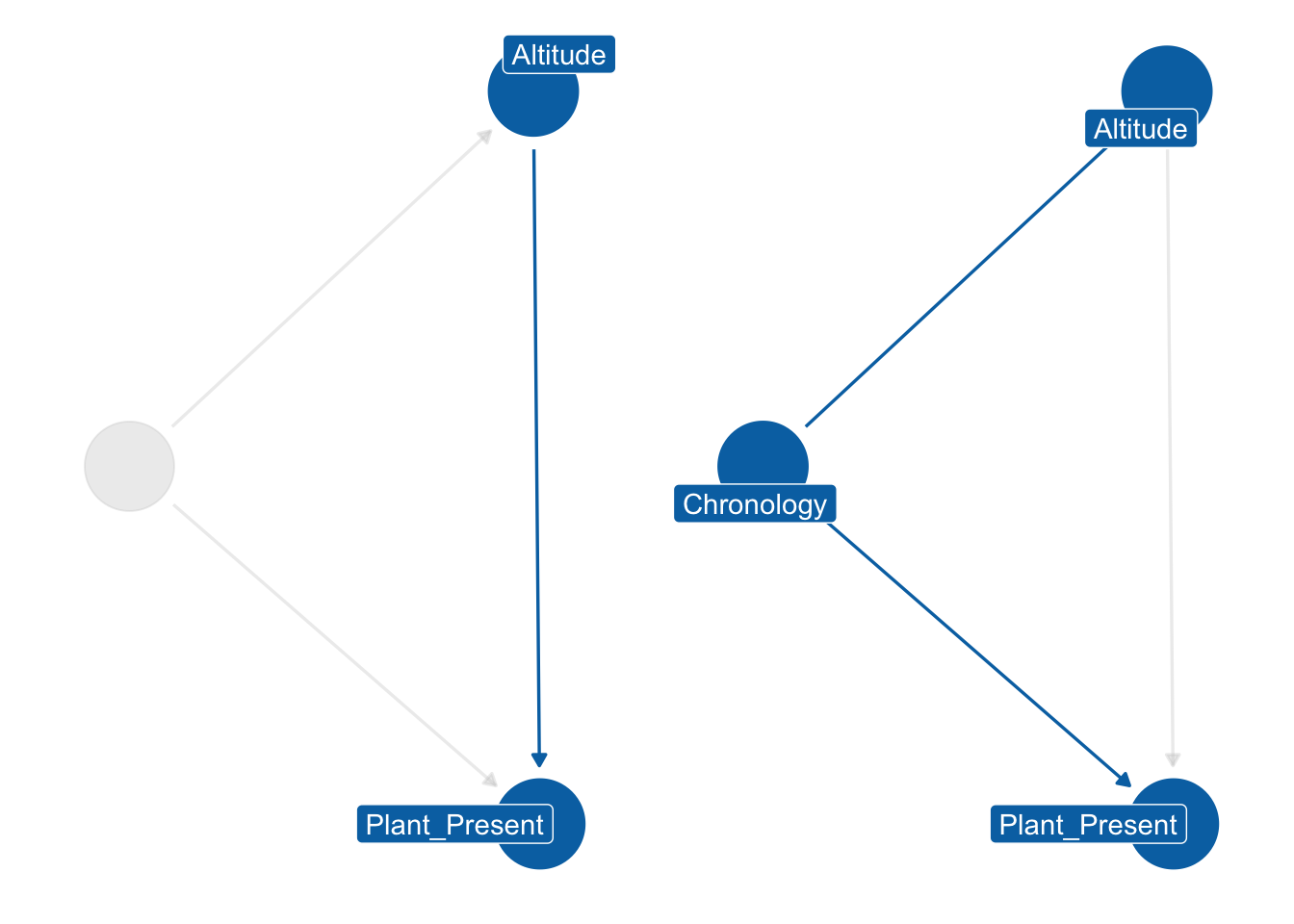
7.5.1 Model specification and priors
In the previous models, an interaction index was used because we were dealing with categorical variables. In this scenario, however, we have a categorical and numerical variable, as we are focusing on the effect of altitude on the presence of plants. The DAG for this case still shows Chronology as a collider, similar to the previous situation. Certainly the time period affects both the likelihood of a plant being present and the altitude of the sites. As shown in Figure 7.25, the distribution of sites varies between different chronological phases. We cannot be certain whether this trend in the data represent real settlement patterns, but for the purposes of this study we need to adjust by Chronology.
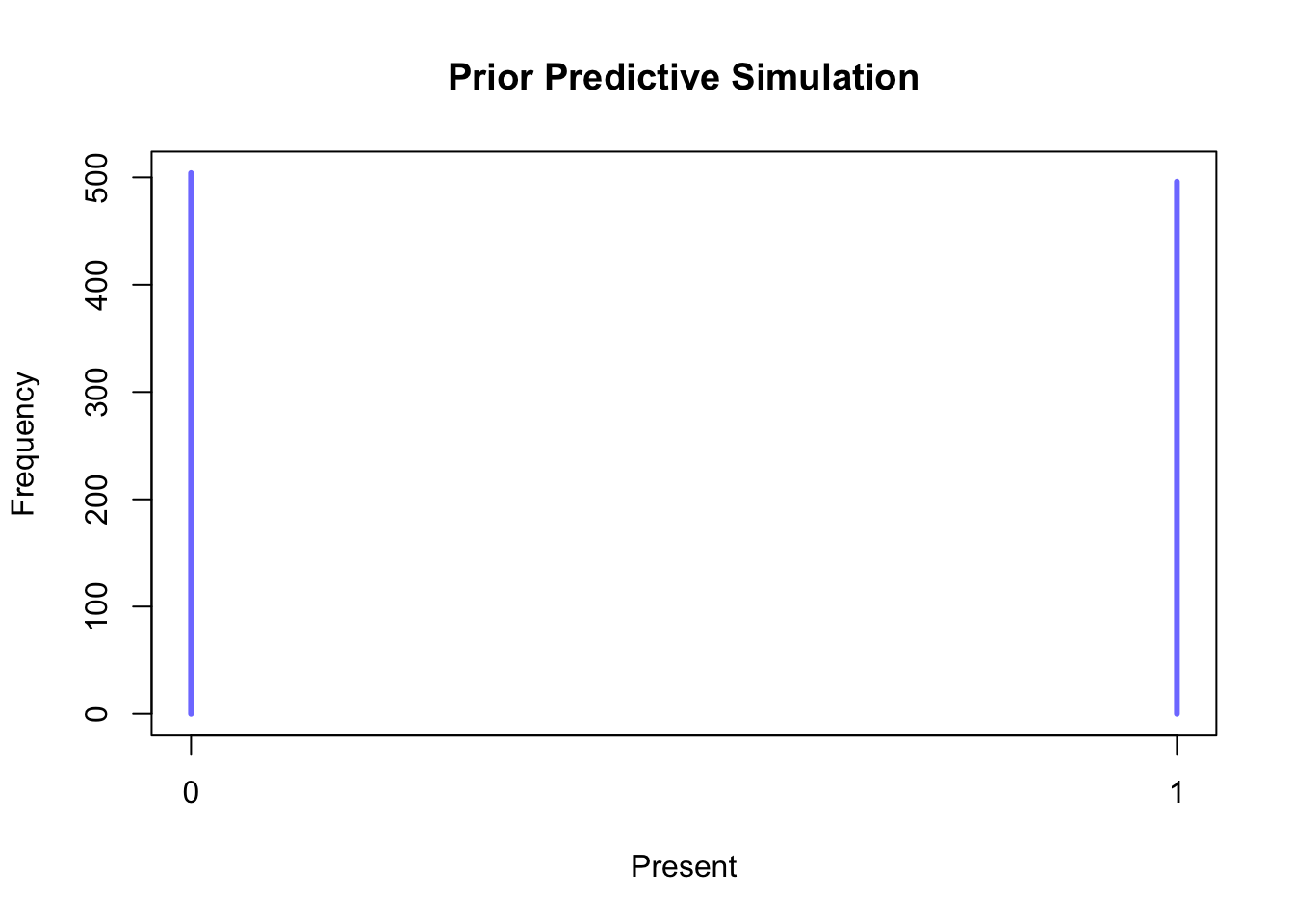
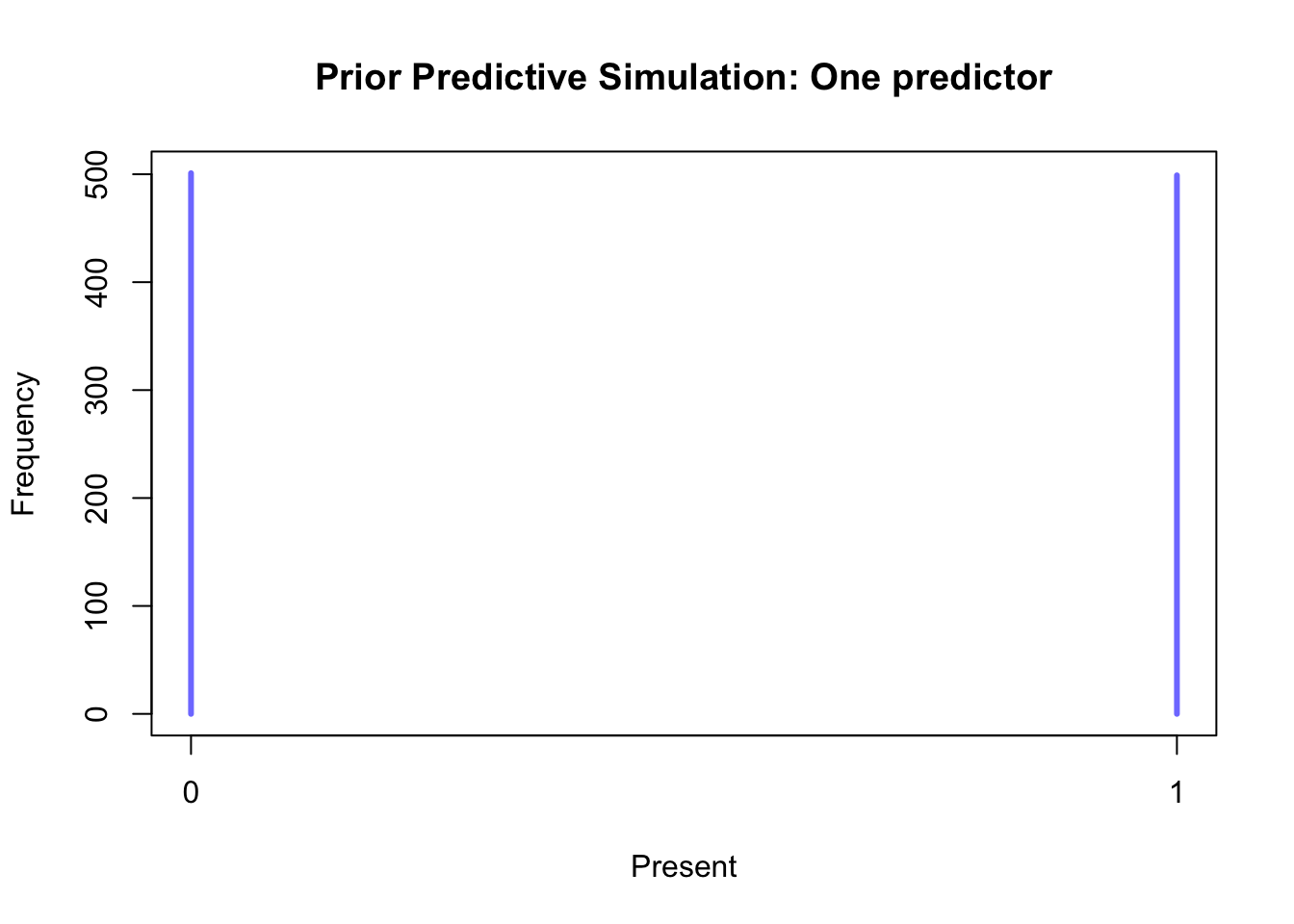
Creating a Bayesian multi-level model to predict the presence of a particular cereal taxon at different elevations is comparable to the binomial models discussed earlier. Since we are only modelling individual taxa, we are dealing with a Bernoulli distribution (in which the number of trials is fixed at 1). Furthermore, we intend to stratify the models by chronology, just as we did previously. For this purpose, we introduce two parameters: a varying intercept \(\alpha\) that carries the chronology index \({[ChrID]}\) (i.e. Roman = 1, late Roman = 2, etc.), and a slope \(\beta\) that is multiplied by the elevation of the \(i\)-th site \(Alt_{i}\). The slope parameter is included to ensure that a change in elevation is reflected in the predicted probability. Both parameters have a weakly informative prior (with a mean of 0 and a standard deviation of 1.5) introduced to make the possible outcomes (present/absent) equally likely in the absence of data. The prior predictive simulation in Figure 7.27 visually demonstrates the effect of these priors, with probabilities piling up on both 0 and 1.
The figures can be interpreted in a comparable manner to the previous ones, which did not incorporate numerical predictors. The x-axis displays elevation expressed in kilometers, while the y-axis presents the probability of discovering a distinct cereal. Similar to previous plots, estimates can be identified across various credible intervals, where wider intervals convey greater uncertainty in the estimation (owing to limited sample sizes or prominent variability in the data observed). For example, it is evident from each plot that the credible interval widens with increasing elevation. In fact, most of the sites examined in Figure 7.25 are situated at lower elevations. The 0.50 HDI, which provides the most reliable probability range, is represented by the darkest shade in the middle of the curves. The following formula shows the components of this model, where the mean probability \(p_{i}\) is modelled by a logit link:
\[ P_{i} \sim Bernoulli(\bar{p}_{i}) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + \beta_{[ChrID]}\cdot Alt_{i} \]
\[ \alpha_{ChrID} \sim Normal(0,1.5) \]
\[ \beta_{ChrID} \sim Normal(0,1.5) \]
7.5.2 Cereals
As planned, we concentrated on modelling the presence of particular types of cereals at varying elevations and chronological phases. This decision was influenced by our interest in economically significant plants and the fact that certain cereal species, such as rye, are more resilient to low temperatures. This makes elevation a crucial factor in farming strategies. The models are classified based on chronology and varying elevations, while acknowledging the significance of certain cultural factors such as geographical area and context type. However, these are not taken into account as having an excessive number of subsets with a relatively small dataset poses a risk. Therefore, we can examine the estimated patterns throughout the entire peninsula.
Free-threshing wheats, which are likely the most cultivated cereals in Italy, demonstrate a robust presence in all four chronological phases at any altitude, with the likelihood of their occurrence gradually increasing towards the early Middle Ages. It is evident that there is no noticeable trend in the prediction curve, and there appears to be no correlation between site elevation and this cereal taxon. Whether it was cultivated everywhere or imported, it is impossible to determine with this dataset. However, the mere presence of this information remains significant. On the contrary, barley shows more pronounced patterns than free-threshing wheats. During the Roman period, and particularly in the late Roman era, there is a notable correlation between the presence of barley and a heightened elevation quota. If the estimated occurrence at sea level is approximately 0.4 (which is still a significant contribution), at around 1100-1200 MSL the prediction increases to a probability of 0.90. This correlation appears to remain strong during the early medieval period, with probabilities ranging from 0.70 (at sea level) to 1. The high probabilities also reflect the significance of this cereal in early medieval agriculture.
Conversely, in the assemblages after the 11th century, the curve seems to be flat, suggesting no correlation and exhibiting greater uncertainty in the data. Additionally, the small number of assemblages for this phase is apparent in the graph, which terminates predictions at approximately 450 MSL due to a lack of available data beyond that altitude (refer to Figure 7.25).
There is a chronological shift evident in the estimated probabilities for emmer, although during the Roman and late Roman periods there is higher uncertainty due to wide HDIs, particularly at high elevations. The estimated means during these two phases imply no correlation, however their credible intervals allow for the possibility of positive or negative trends at higher elevations. In the early Middle Ages, the correlation between the increase in more rustic grains (particularly in the North where some sites are located at higher elevations, see Figure 3.8) and a higher probability of discovering emmer appears to be positive. The correlation remains only marginally positive in the subsequent phase. However, as previously mentioned, the model ceases predictions at 450 MSL.
Similarly to emmer, the posterior predictive simulations for einkorn display significant ambiguity at any stage, particularly beyond 300 MSL. During the Roman period, emmer seems to have been present at greater frequencies in higher altitude sites, while the curves remain flat in subsequent phases, as indicated by the 0.50 HDI. The only visible change is the higher probabilities in the early medieval era.
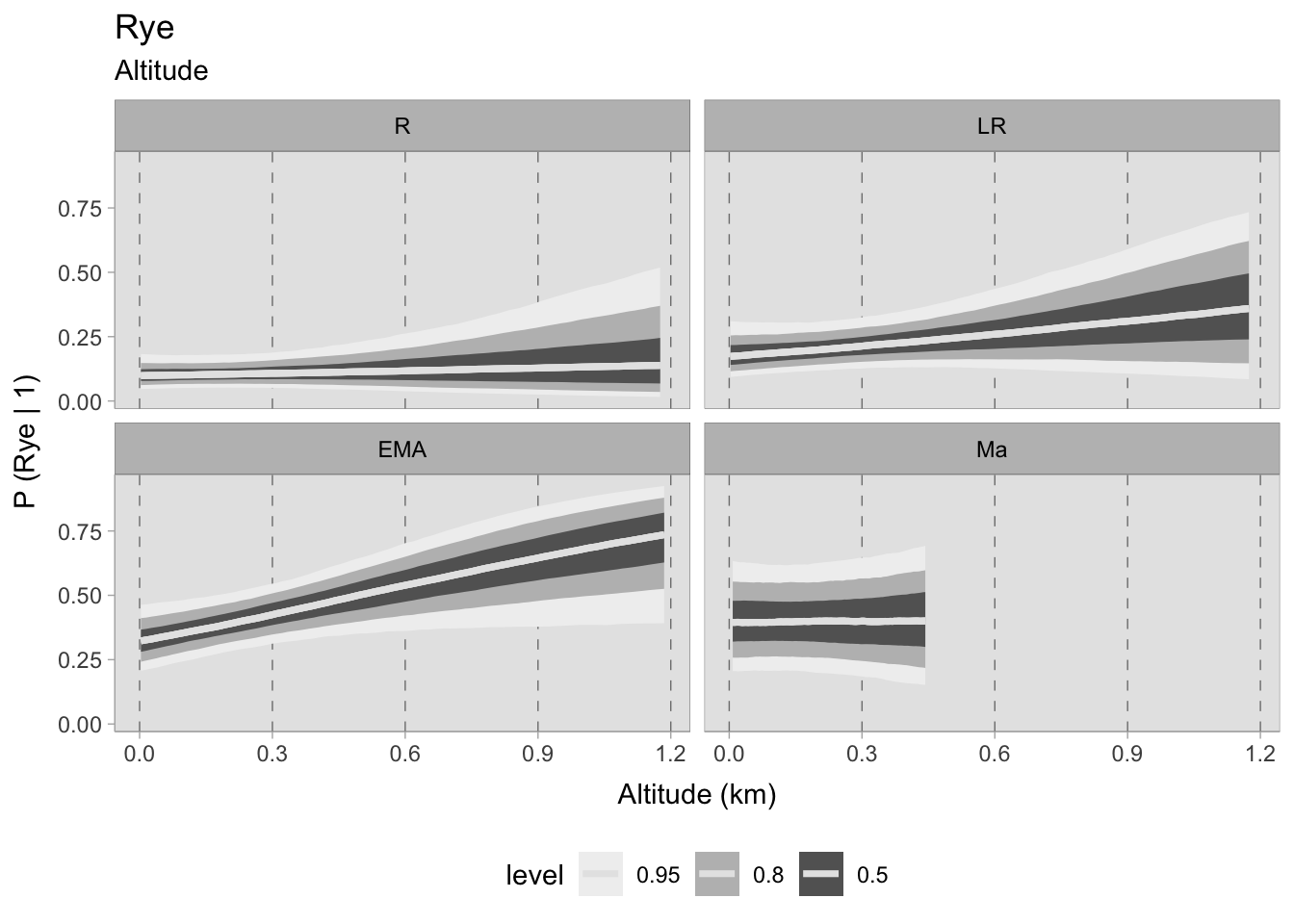
The model for rye produced some interesting results. During the Roman era, the chances of discovering rye on a particular site are minimal, with a slightly higher likelihood at greater elevations. In the later Roman period, the likelihood of identification even at sea level rises, displaying an upward trend on sites located at high elevations, albeit accompanied by greater ambiguity (owing to the limited number of locations at high altitudes). During the early medieval period, rye was found to have a higher probability of growth at sea level with a strong positive correlation to higher altitudes, where it became more established. The correlation was observed to be flat in post-11th century samples. However, this data is unreliable as the HDI values are very large and should not be considered.
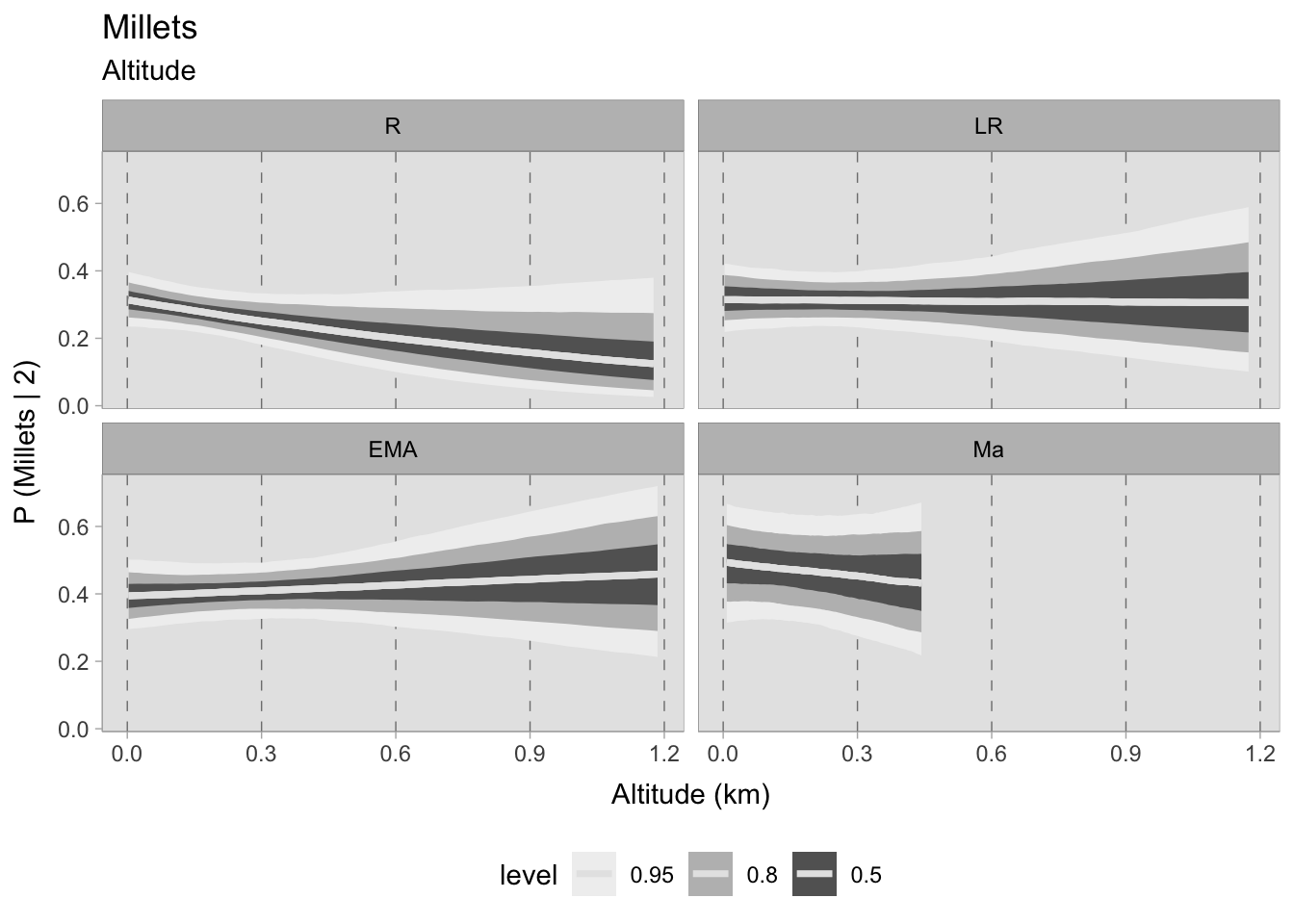
It is more challenging to identify potential patterns in the graph of broomcorn and foxtail millets beyond the Roman phase. In the Roman era, millets were more likely to be found at sea level, with a mean probability of 0.35 and a 0.50 HDI indicating a 0.10-0.25 probability around 1200 MSL. While this particular phase shows a slightly negative trend, the overall probabilities of discovering millets increase in subsequent phases without any apparent correlation to altitude. Only in the post-11th century samples, where the HDI is high, does the negative trend re-emerge.
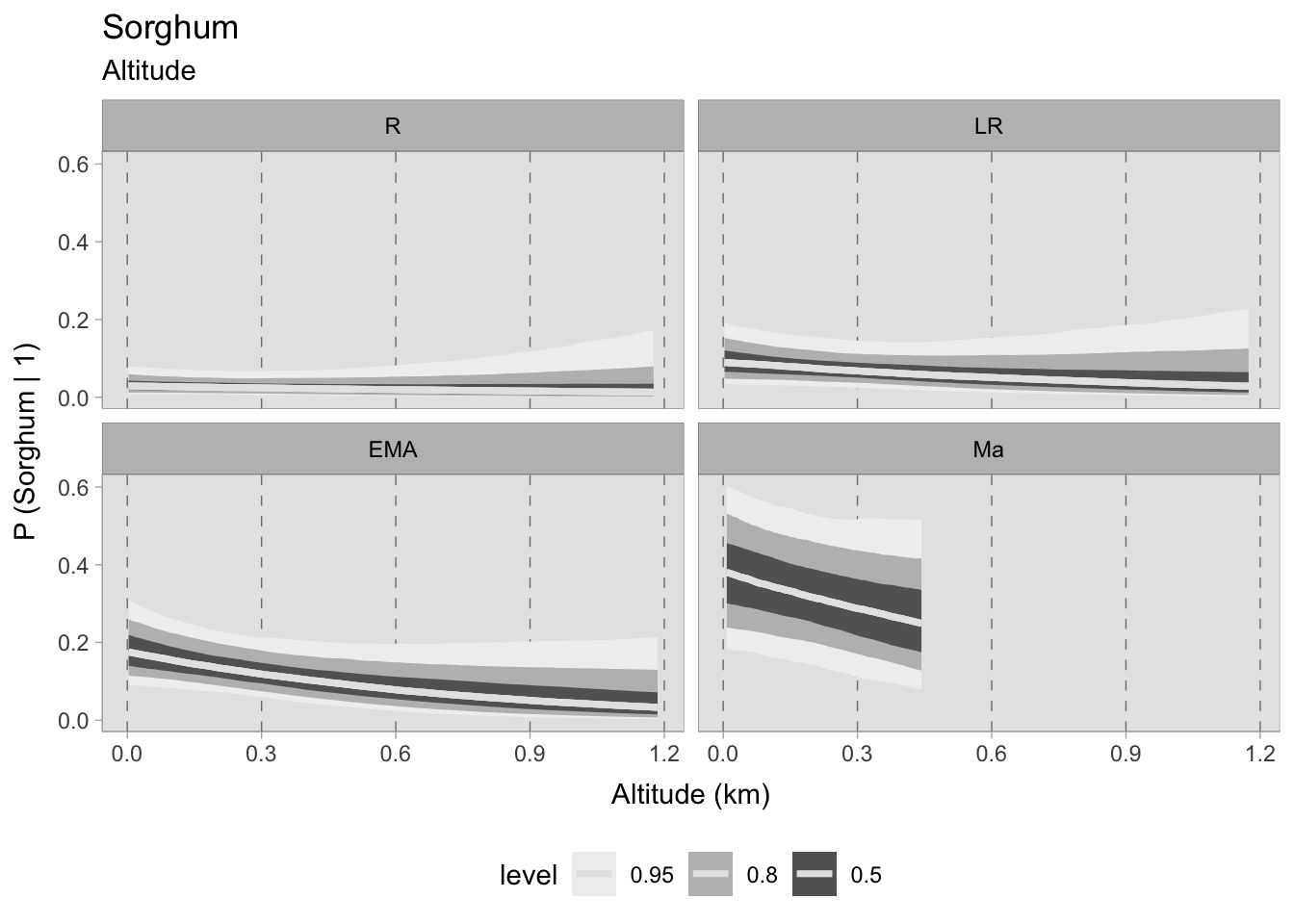
Regarding the final cereal evaluated, sorghum, its presence during the Roman and late Roman periods is scarce, making it difficult to establish any correlation. During the early medieval period, its presence increases and, at sea level, the mean probability is approximately 0.20; however, this probability lessens as altitude increases (having an absolute low of 0 at 1200 MSL). Sorghum is more prevalent in 11th-century samples (mean = 0.40), nevertheless, uncertainty remains high. Although there are wide credible intervals, this phase still indicates a negative correlation. The uncertainty primarily stems from the small sample size rather than the variability in the observed data.
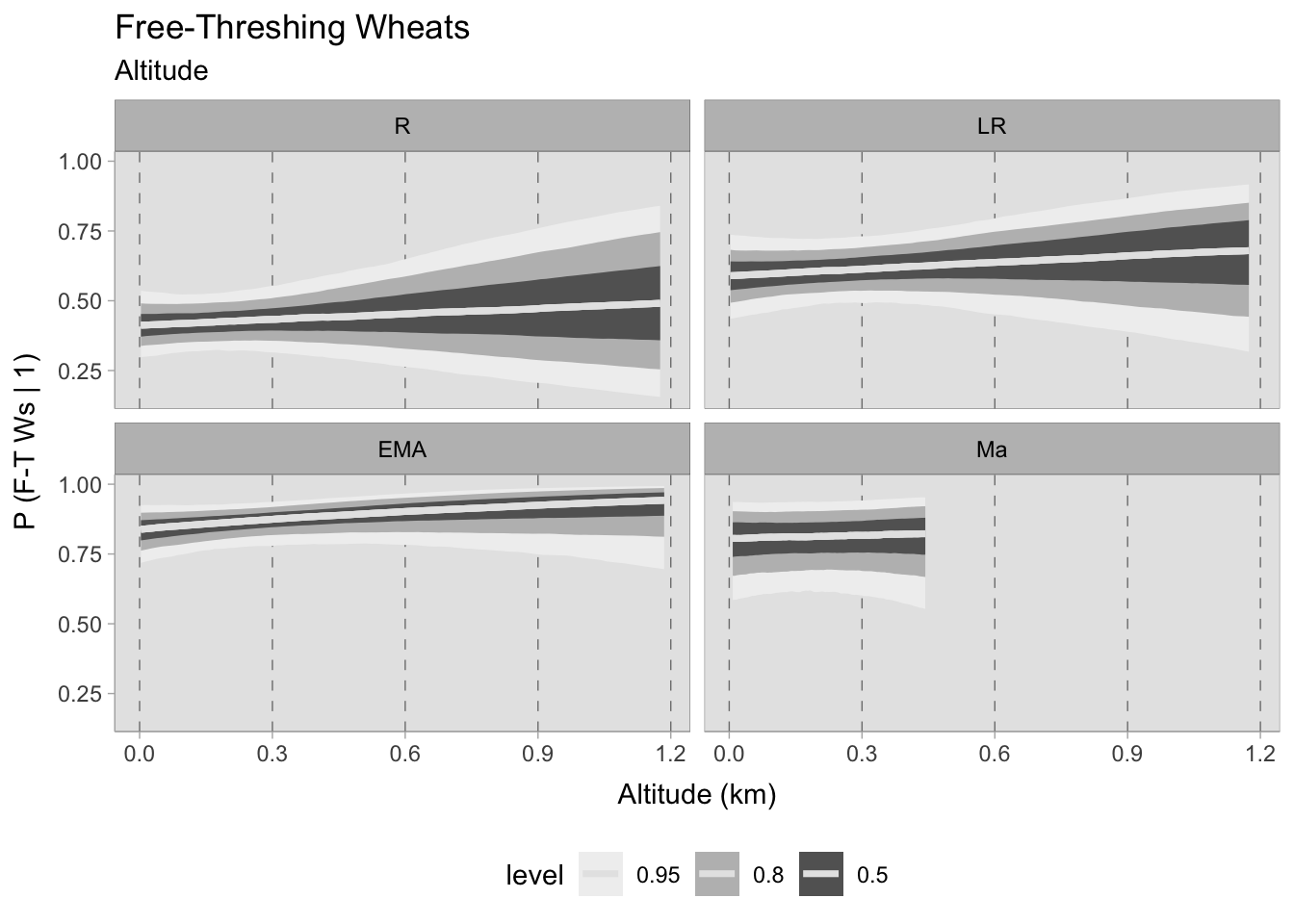
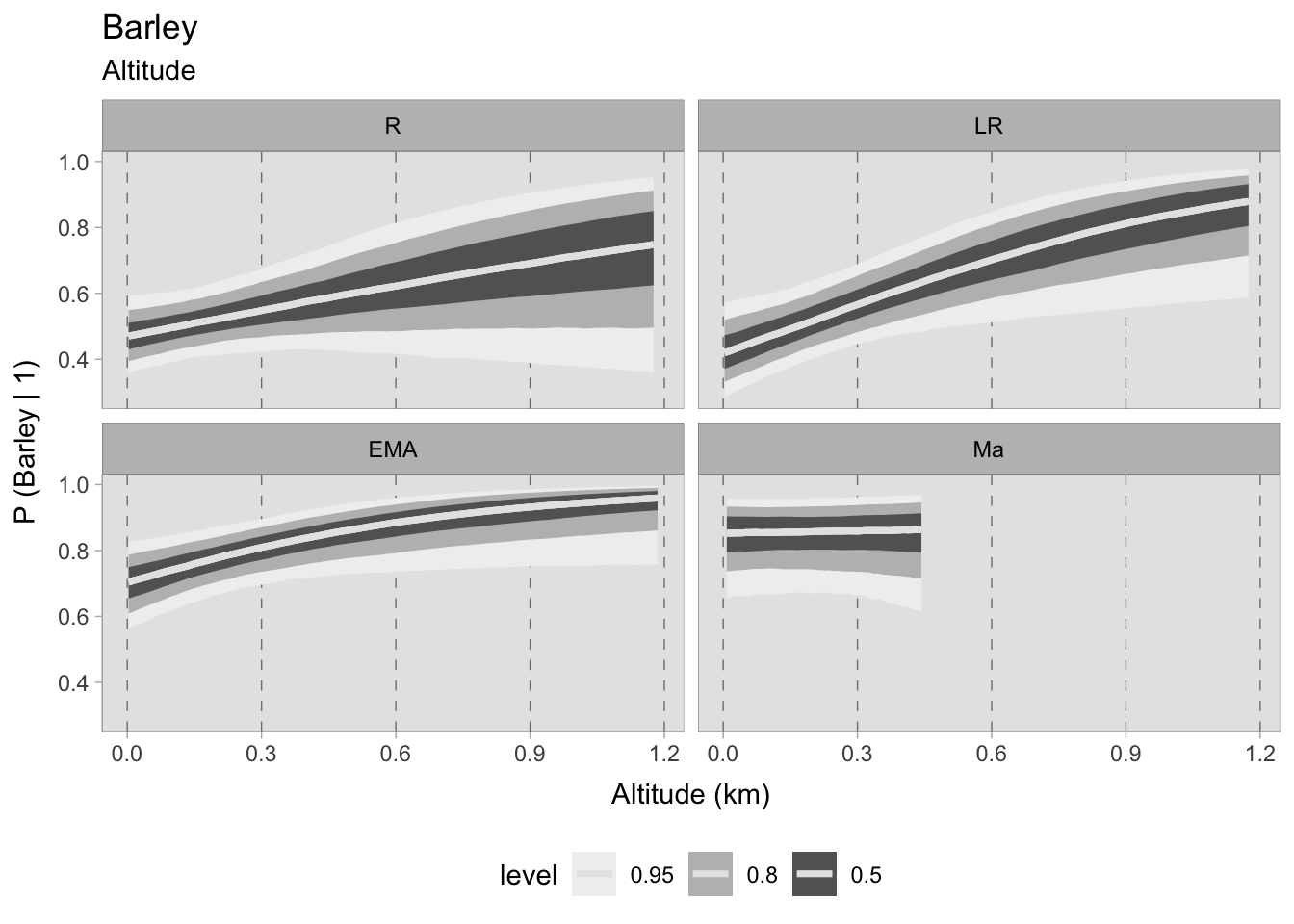
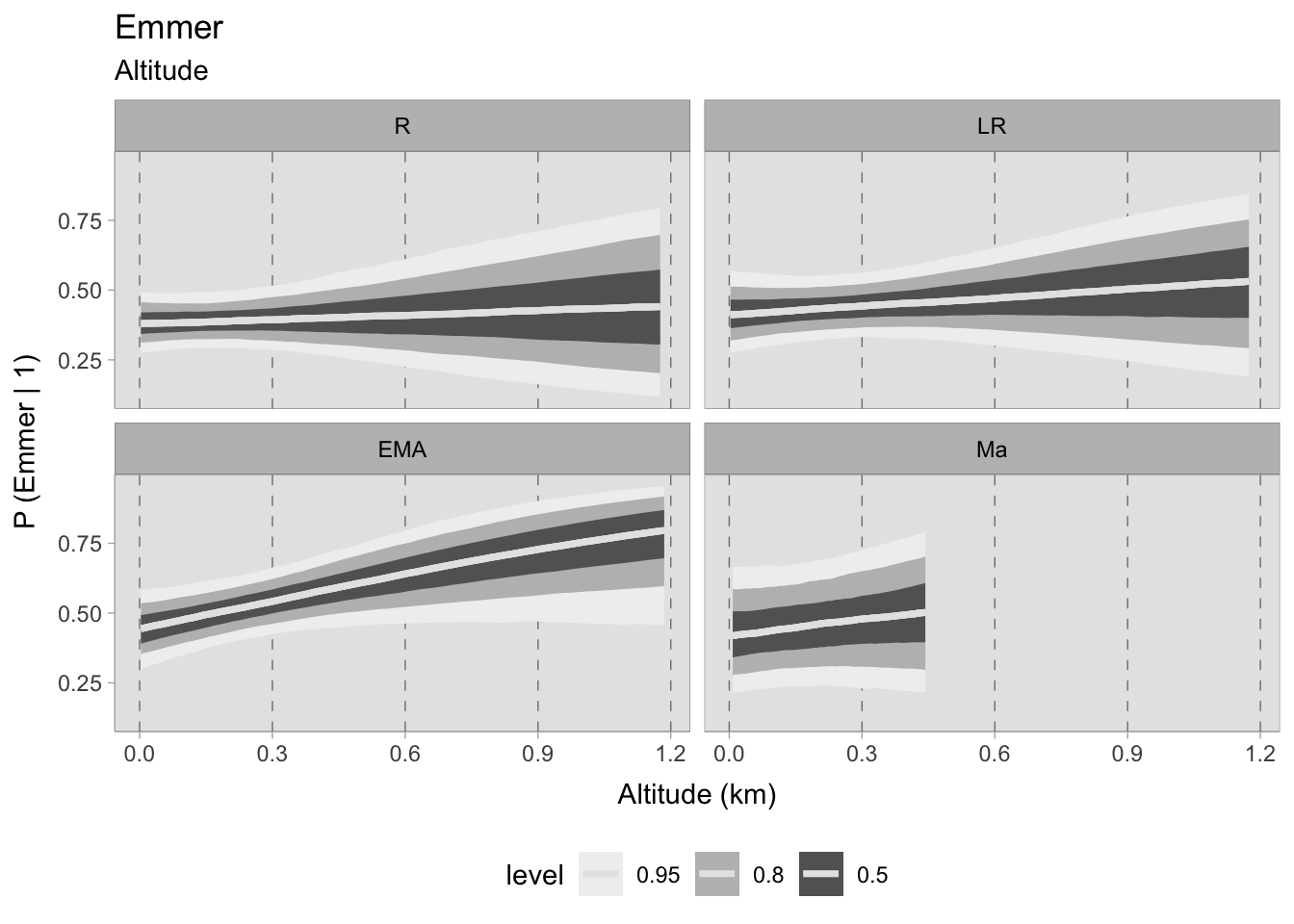
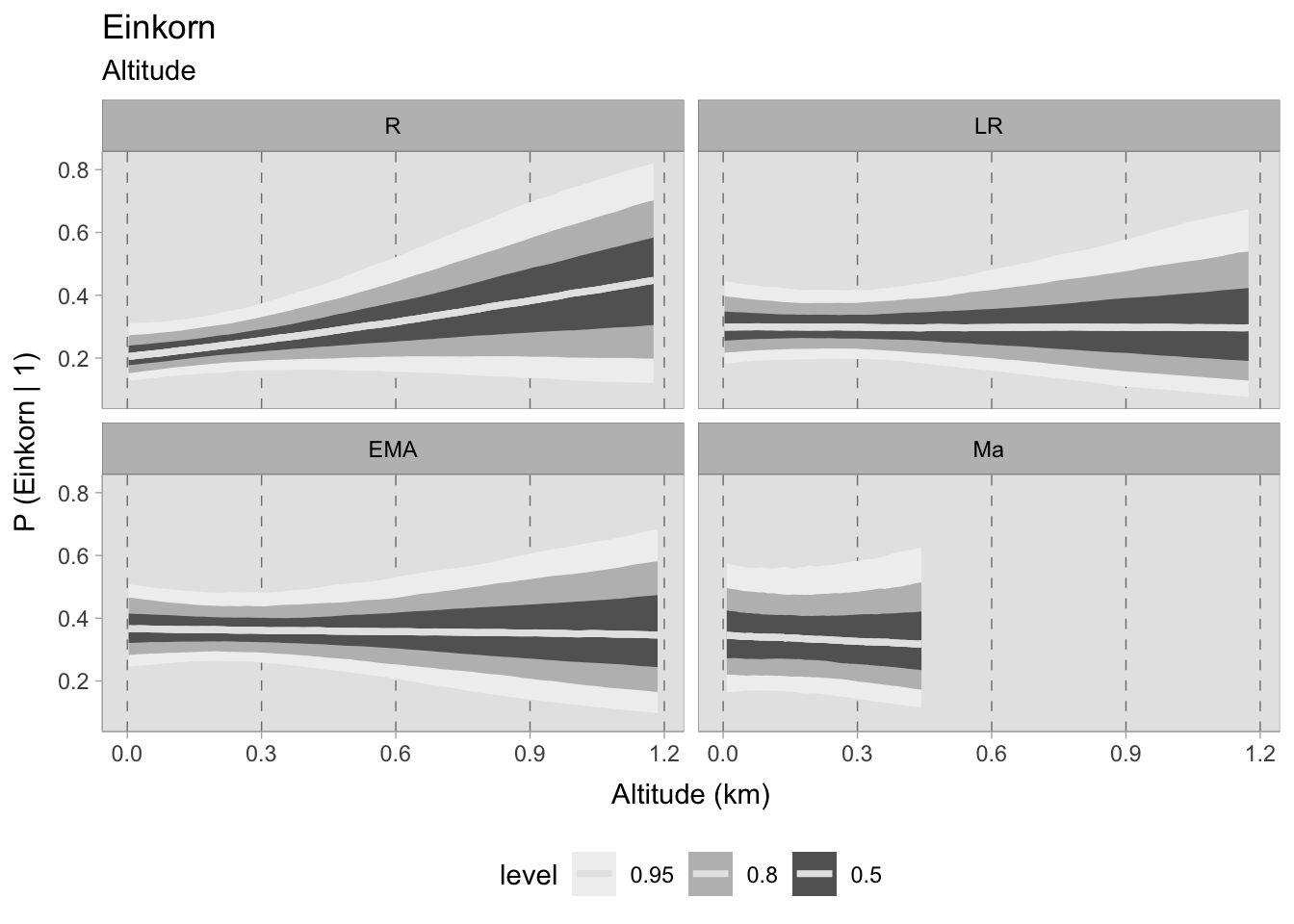
7.5.2.1 Community plot
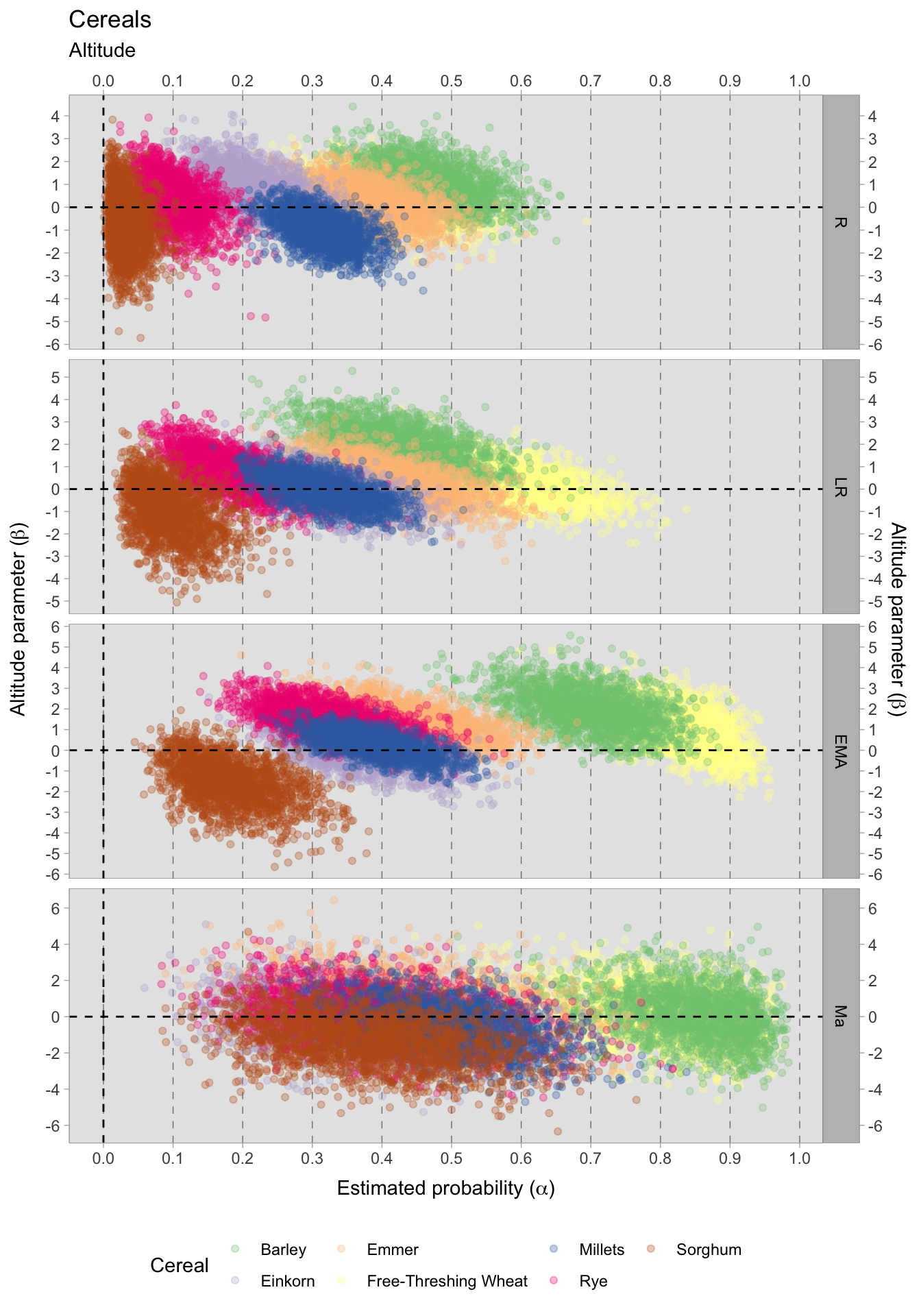
Upon evaluating the impact of elevation changes on each taxon, their posterior distributions have been plotted together on a graph. The x-axis, representing the inverse logit probability of occurrence, provides a user-friendly interpretation within the confines of a standard probability space bounded between 0 and 1. On the other hand, the y-axis displays the estimated slope parameter (\(\beta\)), a varying parameter of our model that has been multiplied with the altitude of each site. This graphical representation not only aids in visualising our findings but also facilitates the comprehensive evaluation of cereals presence. This approach allows us to assess positive or negative correlations within our graph. In addition, the graph highlights the considerable variability in estimating the probability of the presence of certain taxa, mirroring the broad HDIs observed in earlier plots. Figure 7.29 shows that the most significant correlations and variations occurred during the early medieval period. There is a clear positive correlation between higher sites and the presence of free-threshing wheat, barley, rye and emmer. In contrast, altitude shows a negative correlation with sorghum presence. When we move to medieval samples from the 11th century onwards, the picture becomes complex and characterised by high uncertainty: clusters of points hover both above and below 0.
7.5.3 Legumes
Instead of creating separate models for each type of legume, an individual model has been developed for several legumes since they can be grown under similar conditions. This model uses a Binomial distribution instead of a Bernoulli distribution, as the number of legumes under examination - lentil, pea, grass pea, chickpea (Cicer arietinum), and vetches (common vetch, fava bean, Vicia sp.) - is fixed at 7. The model was built using a formula similar to the previous:
\[ F_{i} \sim Binomial(7, \bar{p}_{i} ) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + \beta_{[ChrID]}\cdot Alt_{i} \]
\[ \alpha_{ChrID} \sim Normal(0,1.5) \]
\[ \beta_{ChrID} \sim Normal(0,1.5) \]
The impact of altitude on the discovery of legumes appears to be mild, displaying a slight decreasing trend during the Roman era and a minor positive upturn in the late Roman and early medieval periods. Nonetheless, there is a more pronounced correlation in assemblages from the 11th century, albeit restricted to 450 MSL, which prevents comprehensive analysis.
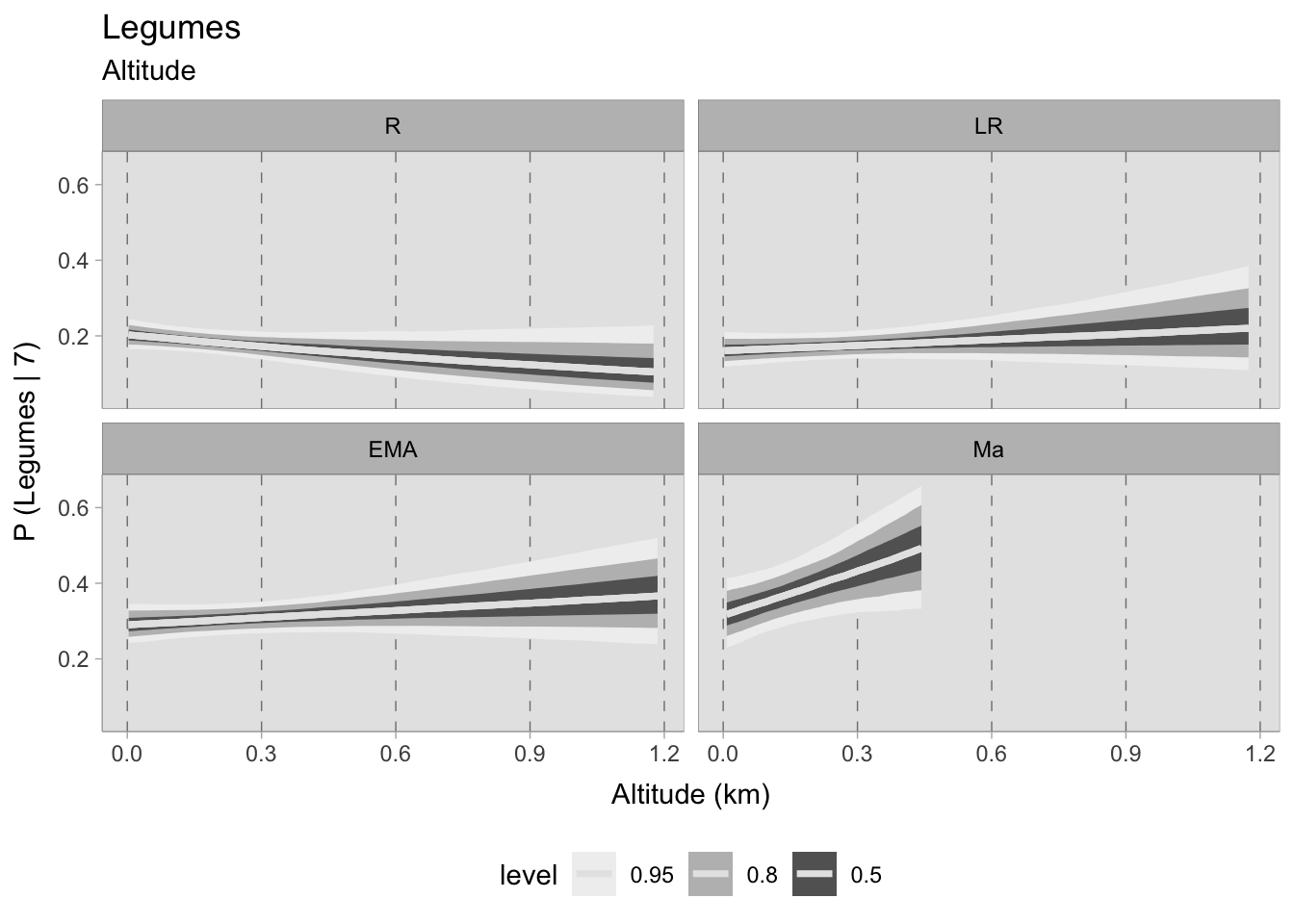
7.5.4 Grapes and olives
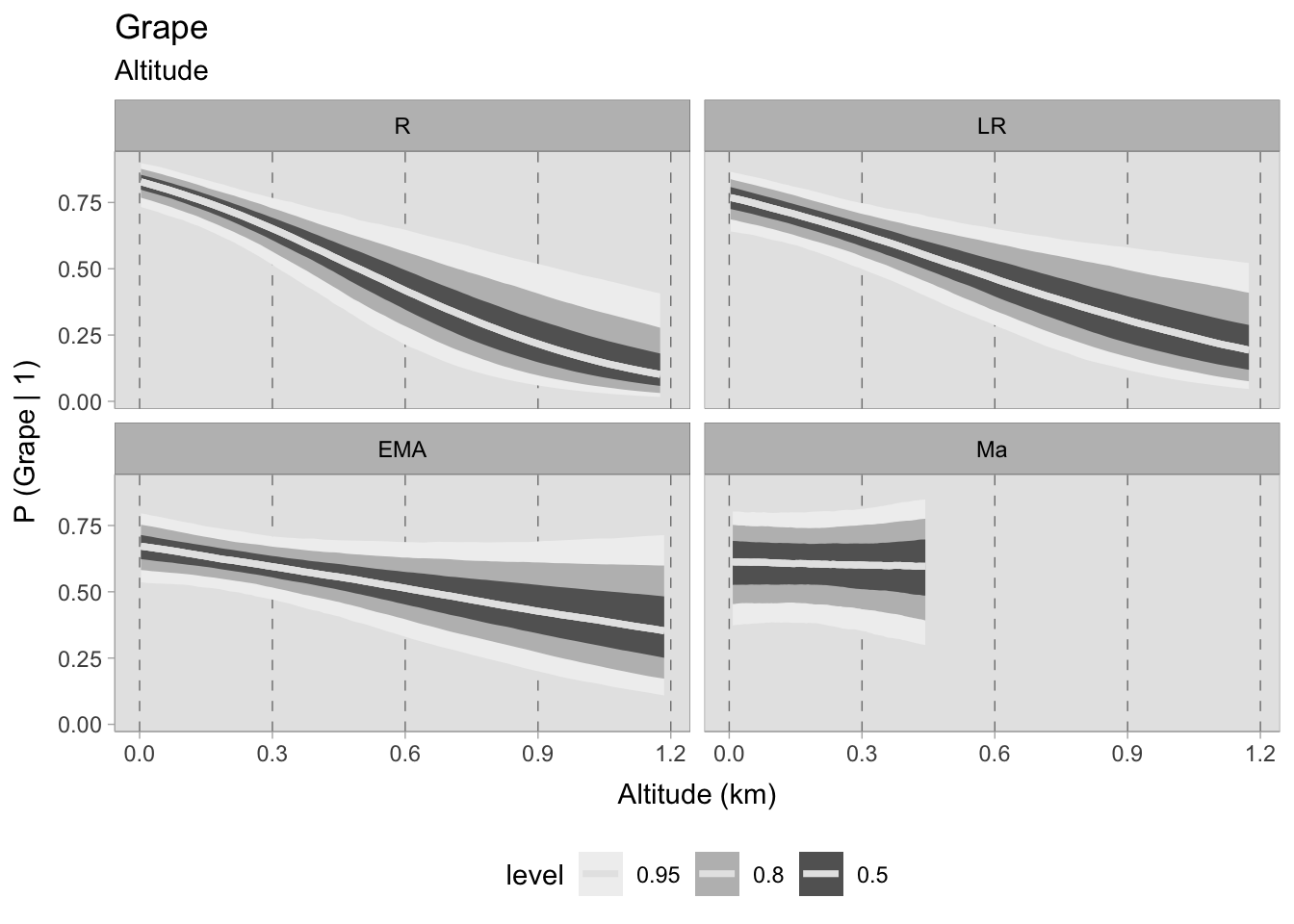
The altitude models for fruits have solely focused on grapes and olives, the two cash crops of interest. Negative correlations with altitude were observed in both models. For grapes, the probabilities at sea level are similar in the Roman and late Roman periods, exceeding 0.75. In subsequent phases, they fall slightly below 0.75. During the first two periods, the probabilities sharply decline upon reaching the 1200 MSL, while in the early medieval period the decrease is less intense. It is important to remind that these models only consider the presence of plant remains. It would be informative to observe the abundance of these remains at different elevations if a sufficiently robust dataset is available. The trend in the 11th century samples does not exhibit any correlation; however, the prediction only extends up to 450 metres above sea level, which would not significantly impede vine cultivation.
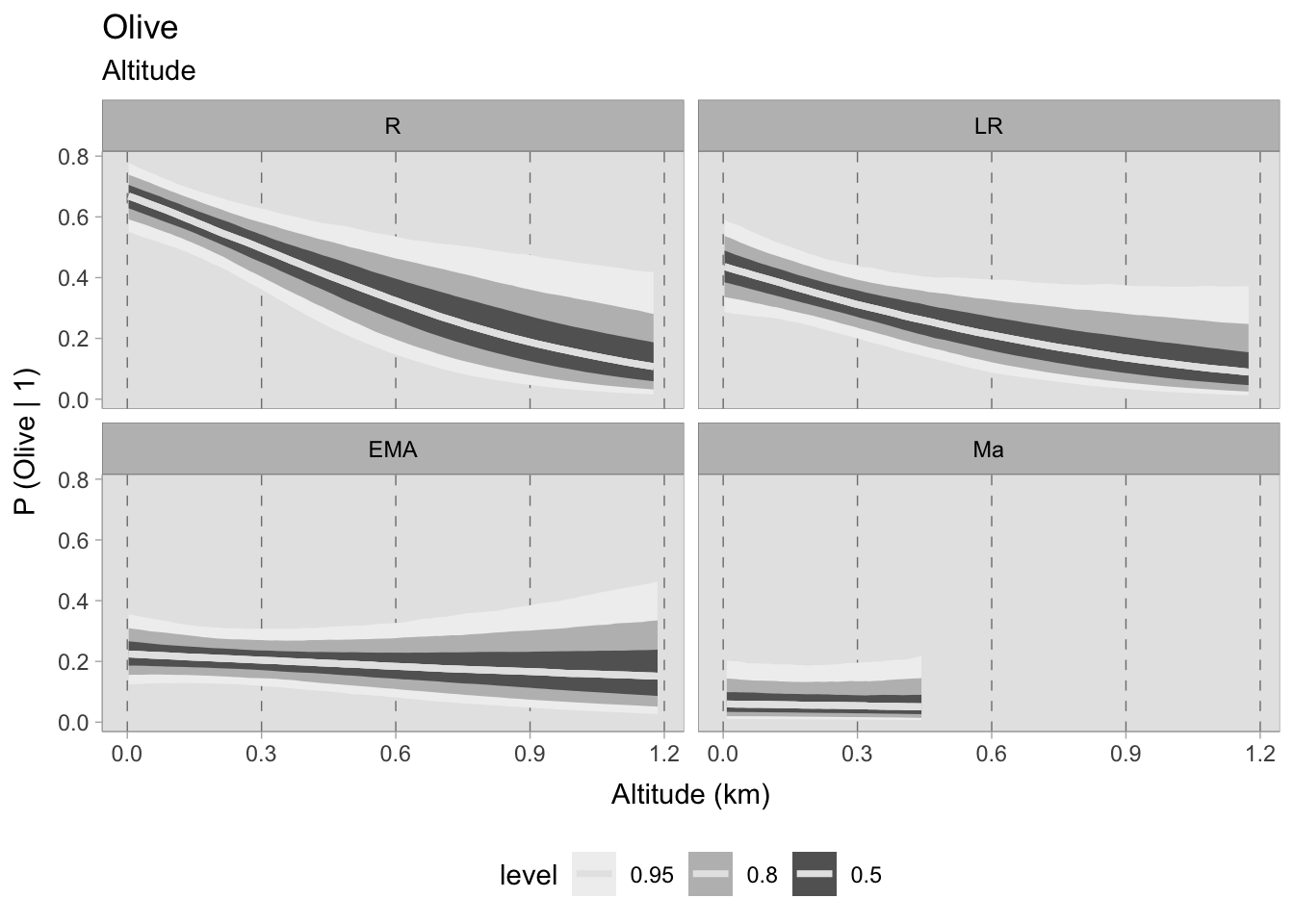
Similarly, the olive models shows a marked decrease in predicted probabilities at higher altitudes during the Roman and late Roman periods. The early medieval dataset still shows a negative correlation, but with a higher uncertainty. For grapes, the medieval samples show no correlations because there are no observations at high altitudes. In fact, olive trees can thrive within the range of altitudes offered by this chronological phase (0-450 MSL).
7.6 Model comparisons
In the concluding remarks of Section 6.6.2, we emphasised the significance of model comparison when conducting Bayesian modelling. So far, categorical predictors have predominantly been employed in models to draw different causal inferences, but numerical predictors are also usually utilised to evaluate the extent to which a predictor’s presence improves the model’s fitness. Indeed, adding further predictors can result in overfitting, leading to certain metrics (such as WAIC, pWAIC, etc.) penalising models with more predictors when comparing them. Farms can accommodate various animals in various climatic conditions, but plants are more vulnerable to external factors. Therefore, in addition to altitude, we included predictors such as average yearly precipitation and temperature. Different models have been developed, with various combinations of predictors, following the common procedure of starting with one predictor and progressively adding more. The aim is to determine whether some variables are more effective in predicting the presence of specific plants than others. For example, we can investigate whether the presence of free-threshing wheats in the sites is influenced more by the yearly rainfall, temperature, or altitude. These figures were derived from 1 km spatial resolution rasters using contemporary climatic data (Fick and Hijmans, 2017). While climatic fluctuations existed during the first millennium (see Section 2.2.2), these models are among the most accurate datasets obtainable.
7.6.1 Precipitation
The presence of crops in a particular region can be influenced by the amount of rainfall. Sorghum and millet are examples of drought-tolerant cereals, while olives are among the most drought-resistant fruits. The following case studies aim to investigate whether increased rainfall has an impact on the presence of certain plant species. In order to assess the effectiveness of this variable in explaining the presence of specific plant taxa in relation to altitude, our approach involved the construction of multi-level models. The first Bernoulli model incorporated a varying effect for each chronology, following the previously established practice of introducing an index \([ChrID]\) to the intercept \(\alpha\). Additionally, we incorporated a varying slope \(bPrecip\)—also contingent on the index \([ChrID]\)—to capture the variability across different subsets. This slope is then multiplied by a constant \(MeanAnnualPrecip_{i}\), representing the standardised mean annual precipitation for each site. Both \(\alpha\) and \(bPrecip\) were then assigned weak priors.
\[ P_{i} \sim Bernoulli(\bar{p}_{i}) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + bPrecip_{[ChrID]}\cdot MeanAnnualPrecip_{i} \]
\[ \alpha_{[ChrID]} \sim Normal(0,1.3) \]
\[ bPrecip_{[ChrID]} \sim Normal(0,1.3) \]
The second model was previously introduced in the altitude section of this chapter, but is being presented again for comparison purposes. This model utilises site altitude \(Alt_{i}\) as its sole predictor, stratified by chronology:
\[ P_{i} \sim Bernoulli(\bar{p}_{i}) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + bAlt_{[ChrID]}\cdot Alt_{i} \]
\[ \alpha_{[ChrID]} \sim Normal(0,1.3) \]
\[ bAlt_{[ChrID]} \sim Normal(0,1.3) \] We subsequently include both altitude and mean annual precipitation in a third model to examine whether the addition of both predictors enhances the fit significantly:
\[ P_{i} \sim Bernoulli(\bar{p}_{i}) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + bAlt_{[ChrID]}\cdot Alt_{i} + bPrecip_{[ChrID]}\cdot MeanAnnualPrecip_{i} \]
\[ \alpha_{[ChrID]} \sim Normal(0,1.3) \]
\[ bAlt_{[ChrID]} \sim Normal(0,1.3) \]
\[ bPrecip_{[ChrID]} \sim Normal(0,1.3) \]
However, our findings suggest that including the average annual rainfall as a predictor did not have a significant impact on model fitness. When comparing the three models using the WAIC measure3, no significant difference was observed:
WAIC SE dWAIC dSE pWAIC weight
m_Cwheat_precip 274.78 12.76 0.00 NA 7.09 0.76
m_CWheat_precip_alt 277.94 13.15 3.15 1.90 9.13 0.16
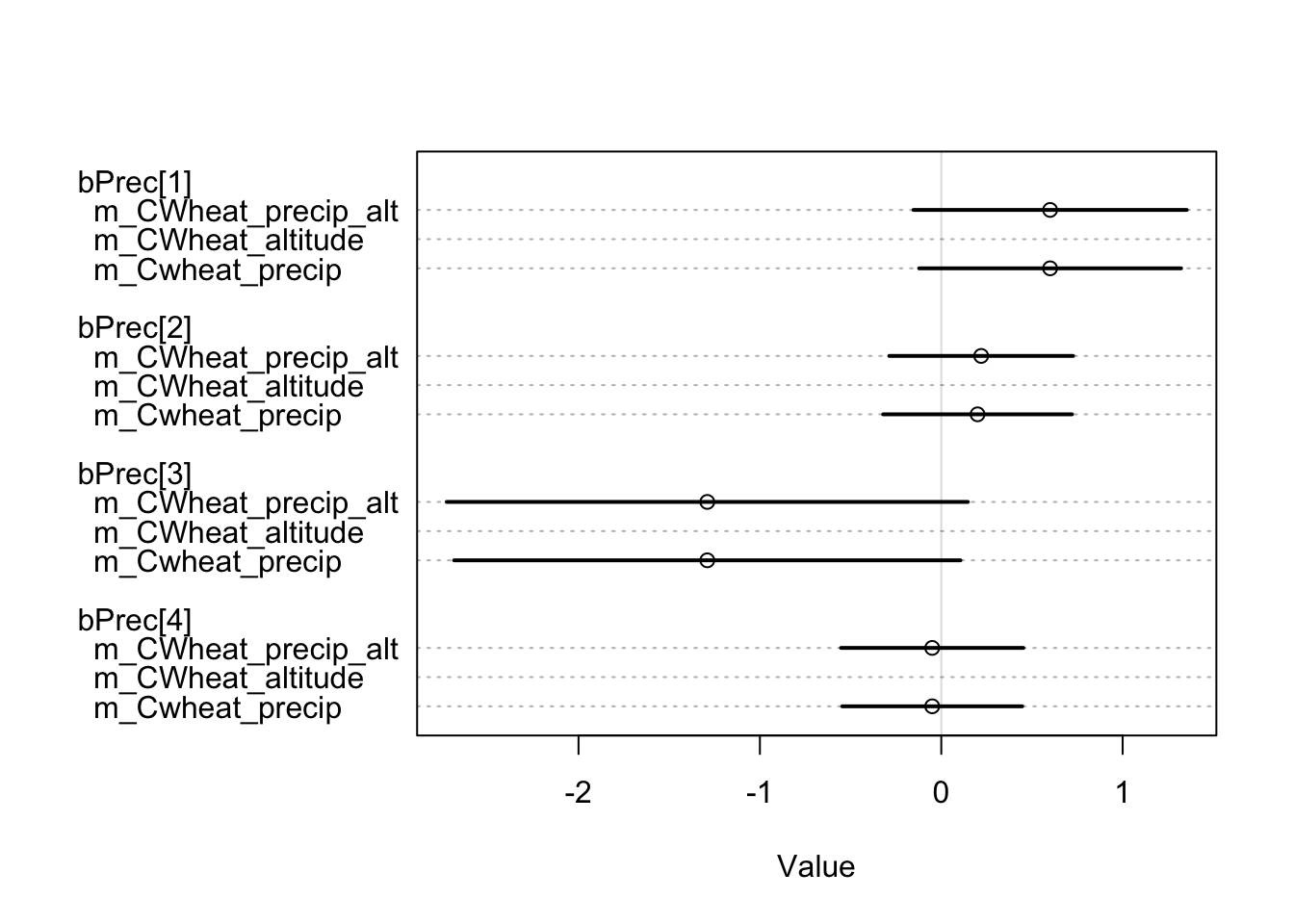
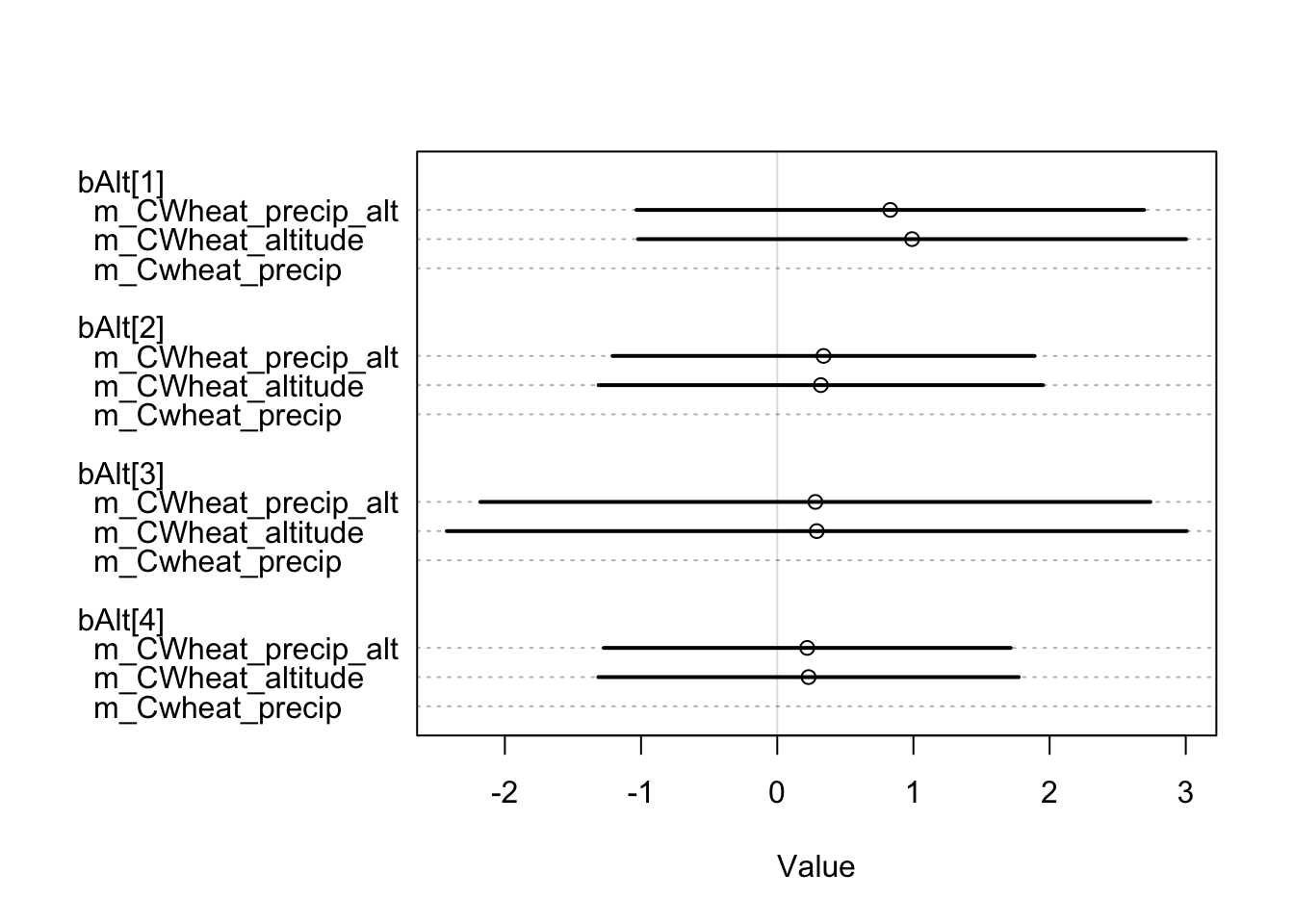
m_CWheat_altitude 279.32 13.53 4.54 5.23 6.05 0.08Although we have only shown the free-threshing wheats models for simplicity, we have created models for various other plants, including non-cereal plants, and found no significant impact of mean annual precipitation on the model. It should be noted that our analysis employs presence/absence measures. While this variable may be beneficial in predicting crop output, it is not appropriate for this particular data conversion. As the disparities are negligible, selecting the optimal predictor is subjective and based on what we consider to be a more relevant factor in explaining historical agricultural phenomena. Therefore, we will rely on altitude.
7.6.2 Temperature
In contrast to the precipitation models, models that utilise the standardised mean annual temperatures as a predictor exhibited diverse results. For each plant that is known to be more vulnerable to extreme temperature conditions or valuable plants, three models were developed. The models’ specifications remain identical to those presented in the preceding section. The first model utilised temperature (\(MeanAnnualTemp_{i}\)) as the sole predictor, stratified by chronology (\([ChrID]\)):
\[ P_{i} \sim Bernoulli(\bar{p}_{i}) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + bTemp_{[ChrID]}\cdot MeanAnnualTemp_{i} \]
\[ \alpha_{[ChrID]} \sim Normal(0,1.3) \]
\[ bTemp_{[ChrID]} \sim Normal(0,1.3) \]
The second model is the altitude model that we have already presented before, and is used as a baseline for comparison:
\[ P_{i} \sim Bernoulli(\bar{p}_{i}) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + bAlt_{[ChrID]}\cdot Alt_{i} \]
\[ \alpha_{[ChrID]} \sim Normal(0,1.3) \]
\[ bAlt_{[ChrID]} \sim Normal(0,1.3) \] Finally, the last model uses two predictors (in addition to chronology), namely site elevation and standardised mean annual temperature:
\[ P_{i} \sim Bernoulli(\bar{p}_{i}) \]
\[ logit(\bar{p}_{i}) = \alpha_{[ChrID]} + bAlt_{[ChrID]}\cdot Alt_{i} + bTemp_{[ChrID]}\cdot MeanAnnualTemp_{i} \]
\[ \alpha_{ChrID} \sim Normal(0,1.3) \]
\[ bAlt_{[ChrID]} \sim Normal(0,1.3) \]
\[ bTemp_{[ChrID]} \sim Normal(0,1.3) \]
Given that the models are identical to those created for the precipitation variable, we do not reproduce the prior predictive simulations.
The investigation into models for free-threshing wheat, rye, legumes, and grape indicates that incorporating an additional predictor does not appear to be warranted. The current models for each of these crops adequately capture the relevant dynamics and trends associated with their respective occurrences.
WAIC SE dWAIC dSE pWAIC weight
m_Cwheat_temperature 278.63 14.34 0.00 NA 7.87 0.51
m_CWheat_altitude 279.32 13.53 0.69 4.21 6.05 0.36
m_CWheat_temperature_alt 281.44 14.70 2.80 0.84 9.51 0.13 WAIC SE dWAIC dSE pWAIC weight
m_Rye_temperature 229.92 18.08 0.00 NA 8.62 0.76
m_Rye_temperature_alt 232.31 18.32 2.39 1.07 10.21 0.23
m_Rye_altitude 240.41 16.10 10.49 9.15 5.99 0.00 WAIC SE dWAIC dSE pWAIC weight
m_Legumes_altitude 890.84 35.15 0.00 NA 14.51 0.84
m_Legumes_temperature 894.49 35.14 3.65 7.65 16.01 0.14
m_Legumes_temperature_alt 897.66 35.27 6.82 6.40 22.01 0.03 WAIC SE dWAIC dSE pWAIC weight
m_grape_altitude 272.71 11.88 0.00 NA 5.37 0.70
m_Grape_temperature_alt 274.57 13.49 1.86 5.36 7.71 0.28
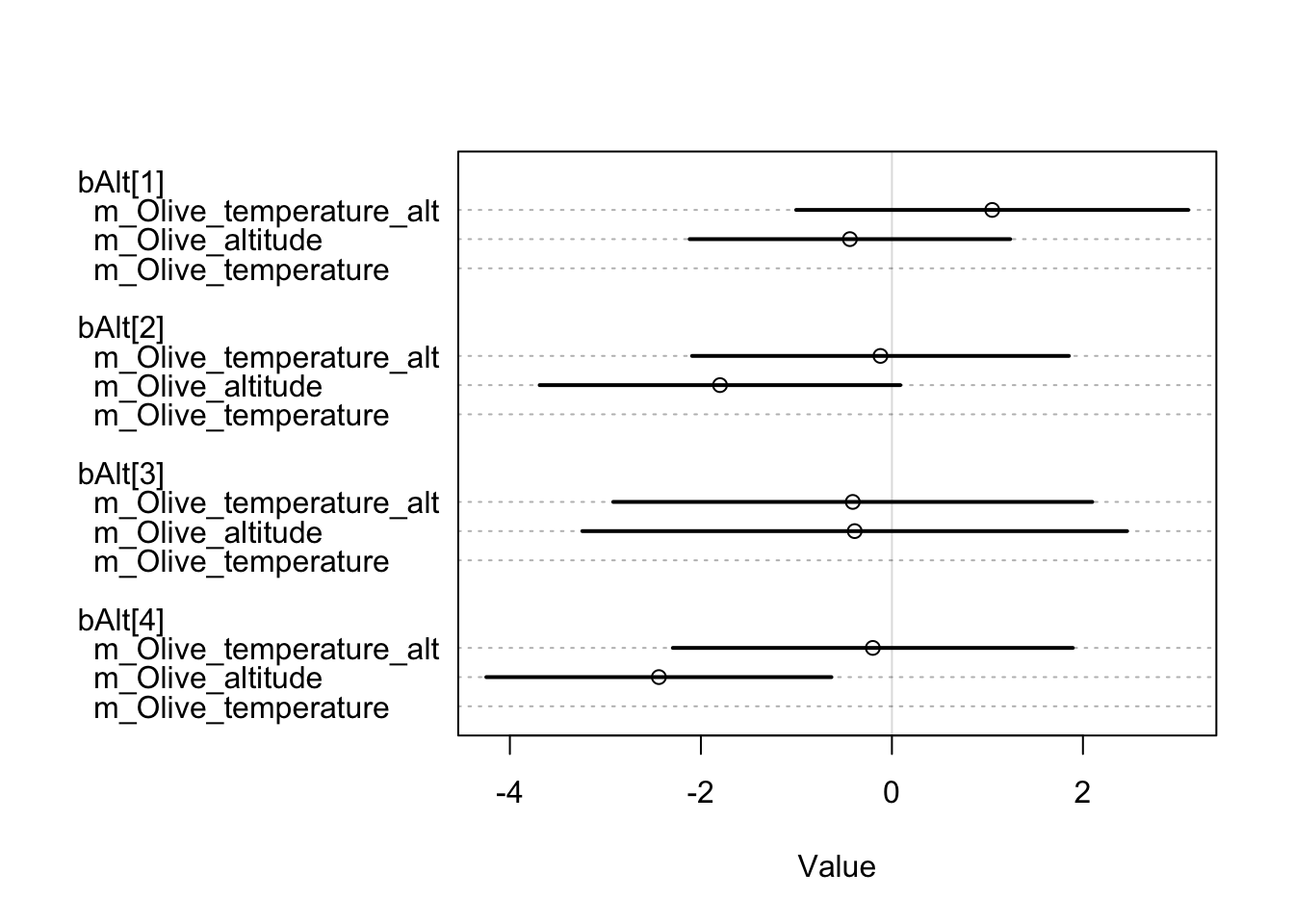
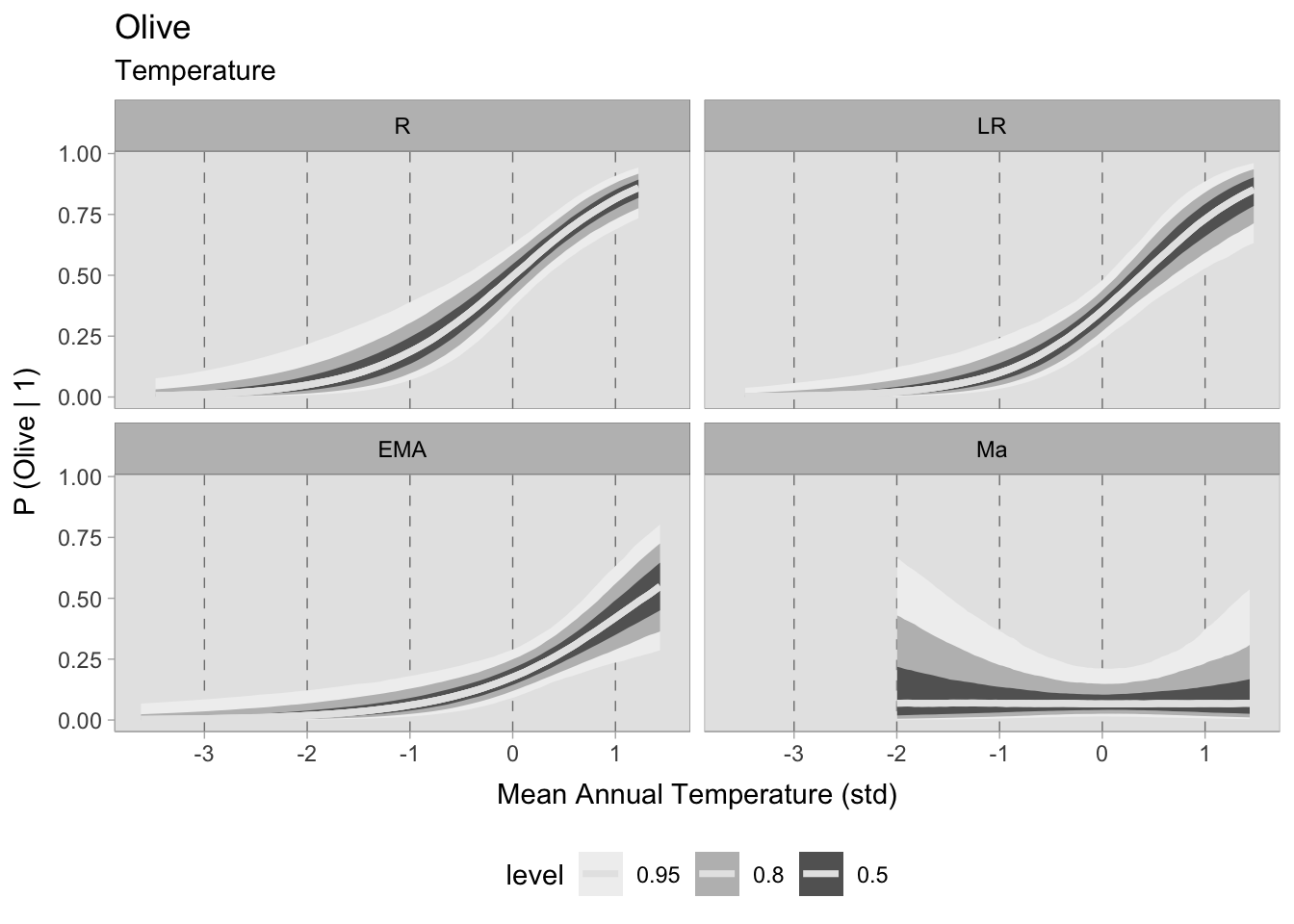
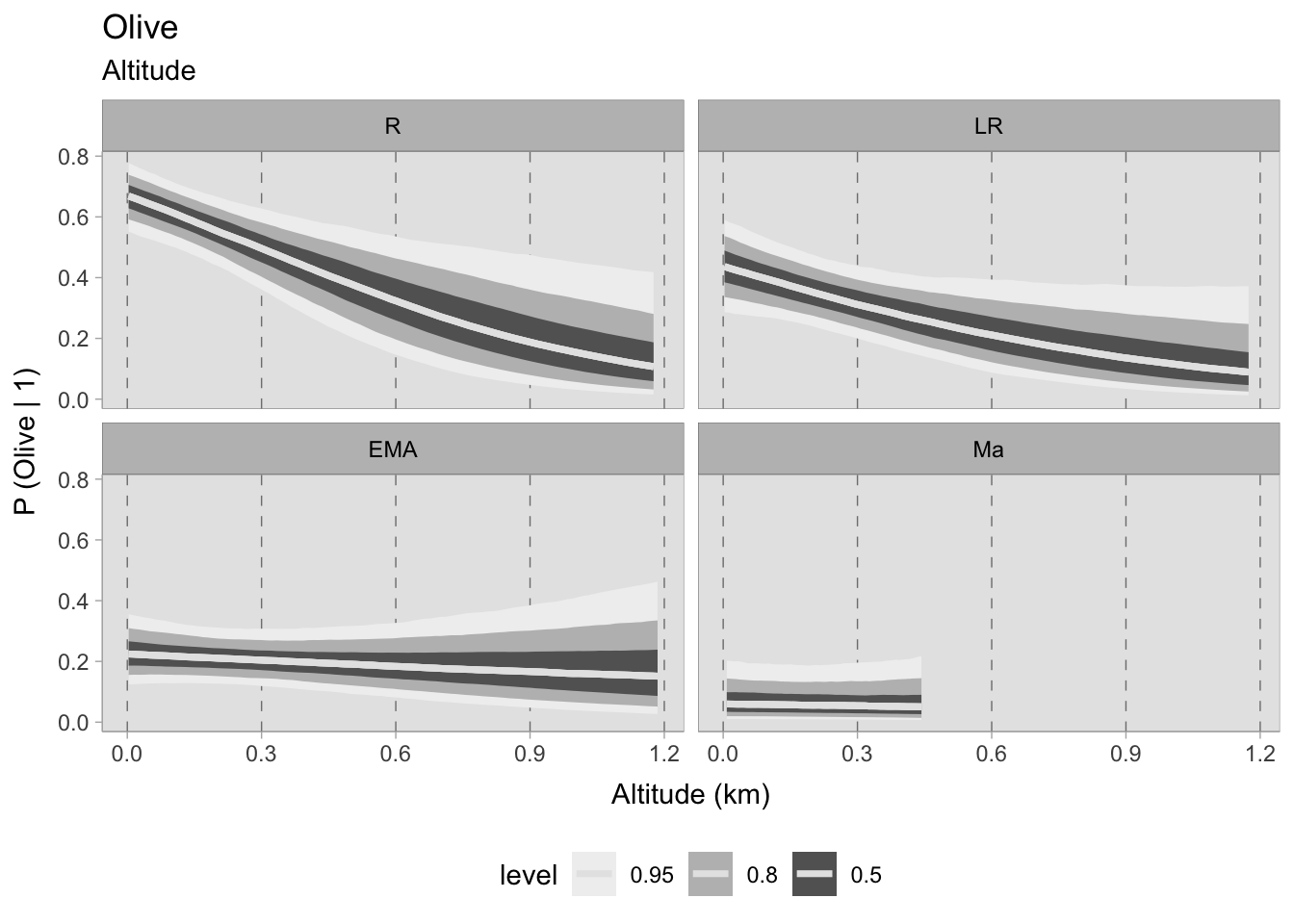
m_Grape_temperature 279.76 13.69 7.05 7.10 6.39 0.02However, the results for olive are worth noting. After a thorough comparison of the three models, it is clear that the choice of a model that includes both temperature and site altitude as explanatory factors is advantageous, although the additional predictor is penalised. The superior fit of this model, compared to the other two, justifies a closer look at the predicted probability of olive occurrence in relation to standardised annual mean temperatures and site altitude (expressed in km). It is remarkable that in each chronology there is minimal dispersion within the 0.50 HDIs.
The temporal differences between these observations seem to remain stable until the 11^th century. It is interesting to note that locations with higher temperatures show a greater propensity to either consume or produce olives. On the contrary, sites located at higher altitudes show a lower probability of participating in the consumption or production of this specific crop.
WAIC SE dWAIC dSE pWAIC weight
m_Olive_temperature_alt 225.67 14.97 0.00 NA 6.39 0.63
m_Olive_temperature 226.70 15.40 1.03 1.29 5.80 0.37
m_Olive_altitude 260.57 12.55 34.90 10.76 4.18 0.00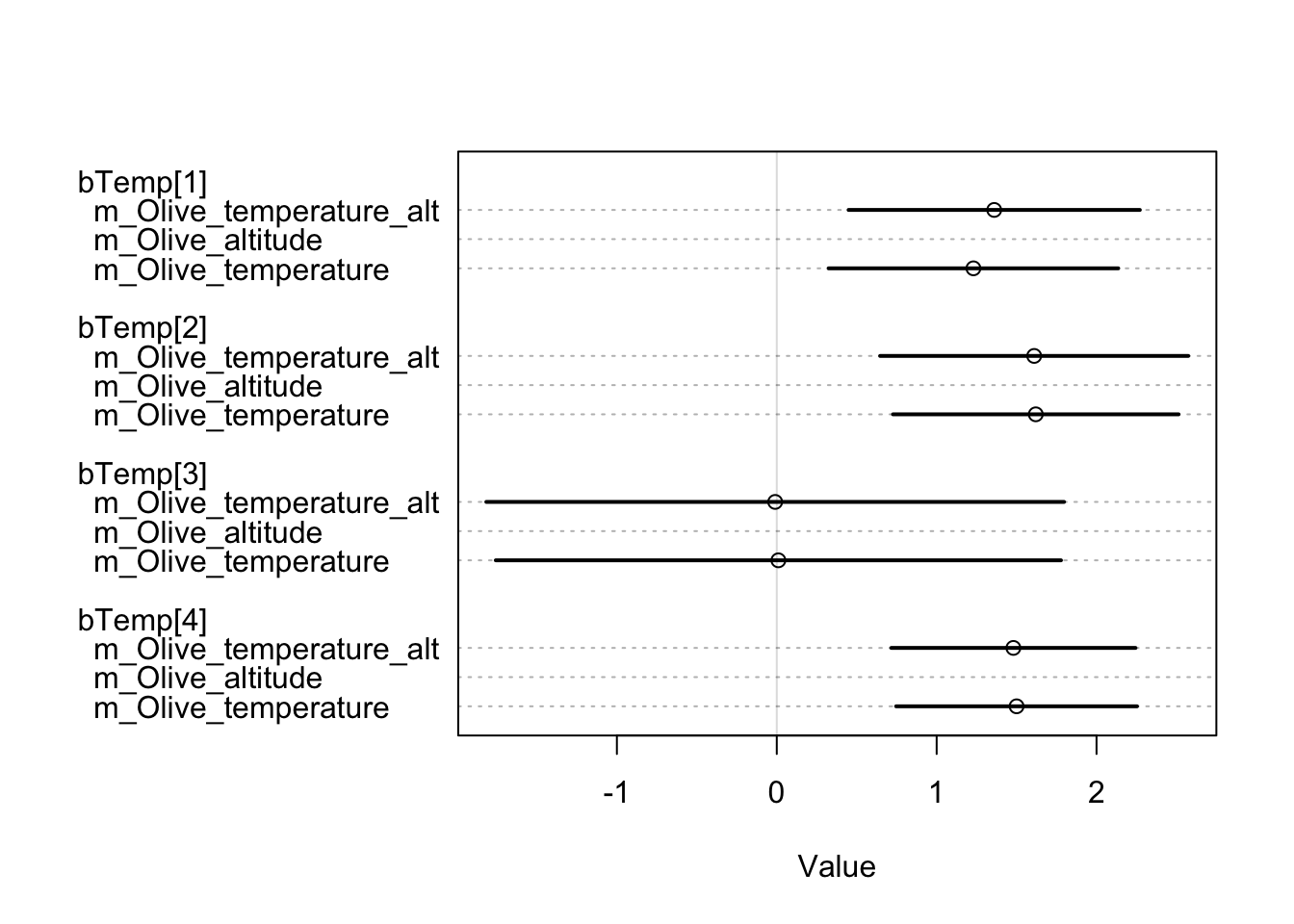
7.7 Cereal proportions
Previous calculations on the archaeobotanical dataset have been based on presence/absence values. This is due to the numerous biases in the samples that distort the distributions. However, this approach does not allow quantitative conclusions to be drawn. From a qualitative point of view, it can be informative to see which sites give different results by calculating the ratio of individual cereal taxa to the total number of cereal grains found in a given sample. In order to explore the quantitative trends, bearing in mind that these results are heavily biased by outliers and sample sizes, summary tables grouped by chronology have been prepared. Two tables in particular are presented here.
The first (Table 7.10) takes into account missing values, so that if a particular taxon was not found in a sample the missing value was converted to 0. The second table (Table 7.11) calculates the means only based on true presences, and missing values are ignored from the computation. In addition to these two tables, a different approach has also been presented. Raw data has been converted into relative ranks, which assigns increasing ranks to the count values (excluding zeros) on a scale of 0 to 1, thus minimizing the impact of extreme outliers and reducing the effects of large differences in values.
Table 7.12 displays the means of the relative ranks, grouped by chronology. In all three approaches, the computations have been based only on totals of cereals attributed to a species. Although these tables allow some considerations on the proportions of cereals in the sites under investigation, it is important to remember that the results might be biased by the quality of the botanical samples.
| Chronology | R | LR | EMA | Ma |
| Common.Wheat | 0.16 | 0.24 | 0.34 | 0.34 |
| Emmer | 0.18 | 0.17 | 0.08 | 0.04 |
| Einkorn | 0.06 | 0.08 | 0.04 | 0.03 |
| Oats | 0.03 | 0.05 | 0.05 | 0.04 |
| Barley | 0.26 | 0.18 | 0.23 | 0.16 |
| Rye | 0.03 | 0.05 | 0.08 | 0.12 |
| Proso.millet | 0.13 | 0.08 | 0.12 | 0.10 |
| Foxtail.millet | 0.14 | 0.16 | 0.05 | 0.10 |
| Sorghum | 0.00 | 0.01 | 0.01 | 0.08 |
| Sample_Size | 6966 | 395210 | 462209 | 32225 |
| Tot_Samples | 70 | 56 | 65 | 18 |
| Chronology | R | LR | EMA | Ma |
| Common.Wheat | 0.33 | 0.37 | 0.39 | 0.41 |
| Emmer | 0.40 | 0.36 | 0.18 | 0.10 |
| Einkorn | 0.28 | 0.24 | 0.12 | 0.12 |
| Oats | 0.28 | 0.20 | 0.13 | 0.13 |
| Barley | 0.46 | 0.30 | 0.28 | 0.17 |
| Rye | 0.35 | 0.26 | 0.22 | 0.34 |
| Proso.millet | 0.40 | 0.27 | 0.27 | 0.19 |
| Foxtail.millet | 0.42 | 0.46 | 0.19 | 0.30 |
| Sorghum | 0.07 | 0.27 | 0.06 | 0.23 |
| Sample_Size | 6966 | 395210 | 462209 | 32225 |
| Tot_Samples | 70 | 56 | 65 | 18 |
| Chronology | R | LR | EMA | Ma |
| Common.Wheat | 0.34 | 0.47 | 0.68 | 0.68 |
| Emmer | 0.33 | 0.32 | 0.27 | 0.22 |
| Einkorn | 0.15 | 0.20 | 0.21 | 0.20 |
| Oats | 0.07 | 0.15 | 0.25 | 0.13 |
| Barley | 0.47 | 0.41 | 0.57 | 0.57 |
| Rye | 0.07 | 0.17 | 0.28 | 0.29 |
| Proso.millet | 0.24 | 0.20 | 0.31 | 0.29 |
| Foxtail.millet | 0.23 | 0.29 | 0.19 | 0.19 |
| Sorghum | 0.01 | 0.03 | 0.06 | 0.19 |
| Sample_Size | 6966 | 395210 | 462209 | 32225 |
| Tot_Samples | 70 | 56 | 65 | 18 |
The Jeffreys interval is a suitable option for the Bayesian credible interval, which is obtained by using the non-informative Jeffreys prior for the binomial proportion \(p\). The Jeffreys prior follows a \(Beta(1/2, 1/2)\) distribution, which is a conjugate prior. The calculation of the posterior distribution for \(p\) can be easily done by using \(Beta(x+ \frac{1}{2}, n-x+\frac{1}{2})\).↩︎
The late Roman values for southern Italy rely solely on 5 samples, of which 3 are from the same site, Salapia (Fiorentino et al., 2022). Thus, the values are not very reliable.↩︎
As a reminder, note that WAIC (and pWAIC) scores hold meaning only within the context of model comparison, with the aim being to favour the lowest score when significant differences exist between models. However, computing this score for a single model lacks significance as it serves purely as a relative measure within the framework of model comparison.↩︎